




Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях.
Модель данных - это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
На рис. 2.3 представлена классификация моделей данных.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.

Рис. 2.3. Классификация моделей данных
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими.
Инфологические модели данных - отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД.
Документальные модели данных - соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) - это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели - это модели, которые основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели - самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
52.Модель «сущность-связь». Основные понятия. Область применения.
Модель сущность-связь (ER-модель) (англ. entity-relationship model, ERM) — модель данных, позволяющая описывать концептуальные схемы предметной области.
ER-модель используется при высокоуровневом (концептуальном) проектировании баз данных. С её помощью можно выделить ключевые сущности и обозначить связи, которые могут устанавливаться между этими сущностями.
Во время проектирования баз данных происходит преобразование ER-модели в конкретную схему базы данных на основе выбранной модели данных (реляционной, объектной, сетевой или др.).
ER-модель представляет собой формальную конструкцию, которая сама по себе не предписывает никаких графических средств её визуализации. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма сущность-связь (ER-диаграмма) (англ. entity-relationship diagram, ERD).
Понятия ER-модель и ER-диаграмма часто ошибочно не различают, хотя для визуализации ER-моделей предложены и другие графические нотации
Нотация Питера Чена

Простая ER-модель MMORPG с использованием нотации Питера Чена
Множества сущностей изображаются в виде прямоугольников, множества отношений изображаются в виде ромбов. Если сущность участвует в отношении, они связаны линией. Если отношение не является обязательным, то линия пунктирная. Атрибуты изображаются в виде овалов и связываются линией с одним отношением или с одной сущностью.[3]
Crow's Foot

Пример отношения между сущностями согласно нотации Crow's Foot
Данная нотация была предложена Гордоном Эверестом (англ. Gordon Everest) под названием Inverted Arrow («перевёрнутая стрелка»), однако сейчас чаще называемая Crow's Foot («воронья лапка») или Fork («вилка»).[4]
Согласно данной нотации, сущность изображается в виде прямоугольника, содержащего её имя, выражаемое существительным.[5] Имя сущности должно быть уникальным в рамках одной модели. При этом, имя сущности — это имя типа, а не конкретного экземпляра данного типа. Экземпляром сущности называется конкретный представитель данной сущности.
Связь изображается линией, которая связывает две сущности, участвующие в отношении. Степень конца связи указывается графически, множественность связи изображается в виде «вилки» на конце связи. Модальность связи так же изображается графически — необязательность связи помечается кружком на конце связи. Именование обычно выражается одним глаголом[5] в изъявительном наклонении настоящего времени: «Имеет», «Принадлежит» и т. д.; или глаголом с поясняющими словами: «Включает в себя», и т.п. Наименование может быть одно для всей связи или два для каждого из концов связи. Во втором случае, название левого конца связи указывается над линией связи, а правого – под линией. Каждое из названий располагаются рядом с сущностью, к которой оно относится.
Атрибуты сущности записываются внутри прямоугольника, изображающего сущность и выражаются существительным в единственном числе (возможно, с уточняющими словами). Среди атрибутов выделяется ключ сущности — неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности.[5]
Прочие нотации
- Bachman notation
- EXPRESS
- IDEF1x
- Martin notation
- (min, max)-Notation
- UML Существует множество инструментов для работы с ER-моделями, вот некоторые из них:
| Название | Платформа | Лицензия * |
| ARIS | Проприетарная | |
| Avolution (англ.) | Проприетарная (EULA) | |
| dbForge Studio for MySQL (англ.) | Microsoft Windows | Проприетарная / бесплатное ПО (для некоммерческого использования) |
| Devgems Data Modeler (англ.) | Microsoft Windows: 2000, XP, Vista | Проприетарная |
| DeZign for Databases (англ.) | Microsoft Windows: NT, 2000, XP, Vista, Windows 7 [software 1] | Проприетарная |
| Dia | Кроссплатформенное ПО | Свободная (GNU GPL)[software 2] |
| ER/Studio (англ.) | Microsoft Windows | Проприетарная |
| ERwin | Microsoft Windows: 2000, XP, Server 2003 [software 3] | Проприетарная |
| Fujaba | Кроссплатформенное ПО (на основе Java) | Свободная (GNU LGPL) |
| Innovator (нем.) | Microsoft Windows 2000, SuSE Linux 10.3, Solaris 8, Red Hat (по запросу) | Проприетарная |
| MEGA International | Microsoft Windows, Web Platform [software 4] | Проприетарная |
| Microsoft Visio | Microsoft Windows | Проприетарная |
| MySQL Workbench | Кроссплатформенное ПО | Свободная (GNU GPL) / проприетарная (EULA) |
| OmniGraffle (англ.) | Mac OS X v10.5+ [software 5] | Проприетарная |
| Oracle Designer (англ.) | Microsoft Windows | Проприетарная |
| PowerDesigner (англ.) | Microsoft Windows | Проприетарная |
| Rational Rose (англ.) | Кроссплатформенное ПО | Проприетарная |
| RISE Editor (англ.) | Microsoft Windows | Проприетарная / бесплатное ПО [software 6] |
| SiSy (нем.) | Microsoft Windows | Проприетарная |
| Sparx Enterprise Architect (англ.) | Microsoft Windows, Linux, Mac OS X (с использованием CrossOver) | Проприетарная[software 7] |
| SQL Maestro | Проприетарная | |
| SQLyog | Microsoft Windows: 4.10+, NT | Бесплатное ПО / проприетарная (EULA) [software 8] |
| StarUML (англ.) | Microsoft Windows | Свободная (модифицированный вариант GNU GPL) |
| System Architect (англ.) | Microsoft Windows | Проприетарная |
| Toad Data Modeler (англ.) | Microsoft Windows | Проприетарная |
| Visual Paradigm (англ.) | Кроссплатформенное ПО | Проприетарная / бесплатное ПО (для некоммерческого использования) [software 9] |
· ^ В столбце "Лицензия" указан тип программного обеспечения - проприетарное (собственническое) или свободное (если известна) лицензия, под которой распространяется данное ПО.
Иерархическая модель данных. Основные понятия. Область применения. Достоинства и недостатки.
Иерархическая модель позволяет строить БД с иерархической древовидной структурой. Структура ИМД описывается в терминах, аналогичных терминам сетевой модели данных.
Дерево – это связный неориентированный граф, который не содержит циклов. Обычно при работе с деревом выделяют какую-то конкретную вершину, определяют её как корень дерева и рассматривают особо – в эту вершину не заходит ни одно ребро. В этом случае дерево становится ориентированным. Ориентация определяется от корня. Дерево как ориентированный граф можно определить следующим образом:
- имеется единственная особая вершина, называемая корнем, в которую не заходит ни одно ребро;
- во все остальные вершины заходит только одно ребро, а исходит произвольное количество ребер;
- граф не содержит циклов.
Конечные вершины, то есть вершины, из которых не выходит ни одной дуги, называются листьями дерева.
В иерархических моделях данных используется ориентация древовидной структуры от корня к листьям. Графическая диаграмма схемы базы данных называется деревом определения. Пример иерархической базы данных приведён на рис.2.4.
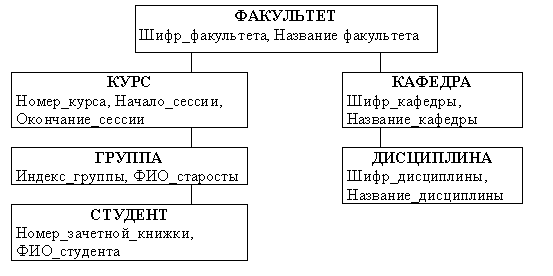
Рис.2.4. Пример иерархической базы данных
Каждая некорневая вершина связана с родительской записью иерархическим групповым отношением. Каждая вершина дерева соответствует сущности ПО, которая характеризуется произвольным количеством атрибутов, связанных с ней отношением 1:1. Атрибуты, связанные с сущностью отношением 1:n, образуют отдельную сущность и переносятся на следующий уровень иерархии. Тип вершины определяется типом сущности и набором её атрибутов. Каждая вершина дерева хранит экземпляры сущностей – записи. Следствием внутренних ограничений иерархической модели является то, что каждому экземпляру зависимой группы в БД соответствует уникальное множество экземпляров родительских групп – по одному экземпляру каждого типа вершин вышестоящих уровней.
В ИМД также предусмотрены специальные способы навигации. Передвижение по дереву всегда начинается с корневой вершины, от которой можно прейти на конкретный экземпляр записи любой вершины следующего уровня. Эта вершина становится текущей вершиной, а экземпляр – текущим экземпляром (записью). От этой записи можно перейти к другой записи данной вершины, к экземпляру записи родительской вершины или к экземпляру записи подчиненной вершины.
Корневая запись дерева должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальные значения только в экземплярах групповых отношений, т.е. на одном и том же уровне иерархии в разных ветвях дерева могут быть экземпляры записей с одинаковыми ключами. Это объясняется тем, что каждая запись идентифицируется полным сцепленным ключом, который образуется путём конкатенации всех ключей экземпляров родительских записей (групп). Таким образом, попасть в любую вершину можно, только проделав полный путь по дереву от корня.
Связи между записями в ИМД обычно выполнены в виде ссылок (т.е. хранятся адреса связанных записей). Подробнее об этом рассказано в разделе 5.5."Организация связей между хранимыми записями".
Основным недостатком ИМД является дублирование данных. Оно вызвано тем, что каждая сущность (атрибут) может подчиняться (принадлежать) только одной родительской сущности. Таким образом, если надо сохранить, например, данные о детях сотрудника, а на предприятии трудится и отец, и мать ребенка, то информацию о детях придётся хранить дважды. Это может вызвать нарушение логической целостности БД при внесении изменений в данные о детях.
Если данные имеют естественную древовидную структуризацию, то использование иерархической модели данных не вызывает проблем. Но на практике часто требуется реализовать структуры данных, отличные от иерархической. Для решения этих задач конкретные СУБД, основанные на ИМД, включают дополнительные средства, облегчающие представление произвольно организованных данных.
54.Сетевая модель данных. Основные понятия. Область применения. Достоинства и недостатки.
Сетевая модель позволяет организовывать БД, структура которых представляется графом общего вида (пример СМД – на рис. 2.3). Организация данных в сетевой модели соответствует структуризации данных по версии CODASYL. Каждая вершина графа хранит экземпляры сущностей (записи) и сведения о групповых отношениях с сущностями других типов. Каждая запись может хранить произвольное количество значений атрибутов (элементов данных и агрегатов), соответствующих экземпляру сущности.
Групповые отношения характеризуют следующие признаки:
1. Способ упорядочения подчинённых записей.
Поддерживаются три способа упорядочения:
- Очередь – добавление в конец списка (FIFO – first input, first output).
- Стек – добавление в начало списка (LIFO – last input, first output).
- Сортировка по значению ключа. В этом случае задаётся ключевое поле (поля), и вновь поступившая запись добавляется в упорядоченный список в соответствии со значением этого поля (значением ключа).
2. Режим включения подчинённых записей.
Режим включения бывает автоматический и ручной.
При автоматическом режиме подчиненная запись связана с записью-владельцем обязательной связью, поэтому она включается в групповое отношение и прикрепляется к записи-владельцу в момент внесения в БД. (Из этого следует, что запись-владелец должна быть внесена в БД до внесения первого экземпляра подчиненной записи.)
При ручном режиме включения подчиненная запись может находиться в БД и не быть прикрепленной к записи-владельцу. Она вручную включается в групповое отношение тогда, когда это отношение (связь) возникает.
3. Режим исключения подчинённых записей.
Режим исключения определяется классом членства. Различают три класса членства: фиксированный, обязательный и необязательный. Записи с фиксированным членством удаляются вместе с записью–владельцем. Записи с обязательным членством должны быть удалены до удаления записи–владельца: владелец, к которому прикреплена хотя бы одна запись с обязательным членством, не может быть удален. Записи с необязательным членством при удалении записи–владельца останутся в БД.
В СМД применяются следующие операции над данными:
- запомнить: внесение информации в БД;
- включить в групповое отношение: установление связей между данными;
- переключить: переход члена набора к другому владельцу;
- обновить: модификация данных;
- извлечь: чтение данных;
- удалить: физическое или логическое удаление данных;
- исключить из группового отношения: разрыв связей между данными.
Связи между записями в СМД обычно выполнены в виде указателей (т.е. каждая запись хранит ссылки на другие однотипные записи и записи, связанные с ней групповыми отношениями). Подробнее об этом рассказано в разделе 5.5."Организация связей между хранимыми записями".
В сетевой модели данных предусмотрены специальные способы навигации и манипулирования данными. Аппарат навигации в графовых моделях служит для установления тех объектов данных, к которым будет применяться очередная операция манипулирования данными. Такие объекты называются текущими. В СМД возможны переходы:
- от текущего экземпляра записи определённого типа к другим экземплярам записи этого же типа;
- из текущей вершины в любую вершину, с которой текущая связана групповым отношением.
Наиболее распространенной и стандартизованной из реализаций СМД является модель CODASYL. В соответствии с ней описание схемы БД осуществляется на языке COBOL, а манипулирование данными – с помощью включающего языка программирования высокого уровня.
Реляционная модель данных. Основные понятия. Область применения. Достоинства и недостатки.
2.4.1. Понятие отношения
Реляционная модель данных была предложена математиком Э.Ф. Коддом (Codd E.F.) в 1970 г. РМД является наиболее широко распространенной моделью данных и единственной из трех основных моделей данных, для которой разработан теоретический базис с использованием теории множеств.
В основе РМД лежит понятие отношения, представляющего собой подмножество декартова произведения доменов. Домен – это множество значений, которое может принимать элемент (например, множество целых чисел, множество комбинаций символов длиной N и т.п.).
Пусть D1, D2 ,…, Dk – произвольные конечные и не обязательно различные множества (домены). Декартово произведение этих множеств определяется следующим образом:

Таким образом, декартово произведение позволяет получить все возможные комбинации элементов исходных множеств.
Пример. Для доменов D1 = (1,2), D2 = (A,B,C) декартово произведение D будет таким:
D = {(1,A), (1,B), (1,C), (2,A), (2,B), (2,C)}.
Подмножество декартова произведения доменов называется отношением.
Элементы отношения называют кортежами. Элементы кортежа принято называть атрибутами. Количество атрибутов кортежа определяет арность отношения. Отношения арности 1 называют унарными, арности 2 – бинарными, арности n – n-арными.
Отношение содержит информацию о сущностях одного типа. Каждый кортеж отношения соответствует одному экземпляру сущности.
Свойства отношений
Отношение обладает двумя основными свойствами:
1. в отношении не должно быть одинаковых кортежей, т.к. это множество;
2. порядок кортежей в отношении несущественен.
Отношение удобно представлять как таблицу, где строка является кортежем, столбец соответствует домену (рис. 2.5, отношение СТУДЕНТЫ).
домен 1........ домен 2................домен 3 (ключ)..............домен 4........домен 5
| Группа | ФИО студента | Номер зачётной книжки | Год рождения | Стипендия |
| С–72 | Волкова Елена Павловна | С-12298 | 566.40 | |
| С–91 | Белов Сергей Юрьевич | С-12299 | 400.00 | |
| ... | ||||
| С–72 | Фролов Юрий Вадимович | С-14407 |
Рис.2.5. Пример табличной формы представления отношения
Отношение имеет имя, которое отличает его от имён всех других отношений. Атрибутам реляционного отношения назначаются имена, уникальные в рамках отношения. Обращение к отношению происходит по его имени, а обращение к атрибуту – по имени отношения и имени атрибута.
Каждый атрибут определён на некотором домене, несколько атрибутов отношения могут быть определены на одном и том же домене (например, номера рабочего и домашнего телефона). Домен задаётся типом данных и ограничениями целостности, например, оклад – это число больше нуля. Значение атрибута может быть не определено в момент внесения записи в БД. Для таких случаев предусмотрено специальное значение – null, которое можно интерпретировать как "неизвестное значение".
Ключ отношения – это атрибут, значения которого идентифицируют кортеж. Таким образом, ключ имеет уникальные в рамках отношения значения. (На рис. 2.5 ключ выделен полужирным шрифтом). Если ключ состоит из нескольких атрибутов, он называется составным. Ключей может быть несколько; основной ключ – первичный, его значения не могут обновляться. Другие ключи называются возможными или потенциальными ключами.
РМД не поддерживает групповые отношения. Для связей между отношениями используются внешние ключи. Внешний ключ – это атрибут подчиненного отношения, который является копией первичного (или уникального) ключа родительского отношения. (Пример – отношение ДЕТИ, связанное с отношением СТУДЕНТЫ по внешнему ключу Номер зачётной книжки, рис. 2.6). Фактически, внешние ключи логически связывают экземпляры сущностей разных типов между собой. Т.о., внешний ключ можно трактовать как ограничение целостности на две таблицы, в соответствии с которым множество значений внешнего ключа является подмножеством значений ключа родительской таблицы. Если связь необязательная, то значение внешнего ключа может быть неопределённым (null).
| Номер зачётной книжки | Имя, отчество ребенка | Дата рождения |
| С-12298 | Антон Павлович | 01.12.01 |
| С-12298 | Юлия Павловна | 01.12.01 |
| С-12299 | Ольга Сергеевна | 16.04.02 |
Рис.2.6. Связь отношений "Студенты" и "Дети" по внешнему ключу
Перечень атрибутов отношения с их типами данных и размерами определяют схему отношения. Отношения, построенные по одинаковой схеме, называют односхемными; по различным схемам – разносхемными.
Все операции над данными в РМД выполняются над отношением и требуют задания имени отношения. Если операция применяется к части отношения, то может потребоваться идентификация кортежа или группы кортежей и задания имён атрибутов. В РМД используются следующие операции над данными:
- запомнить: внесение информации в БД (требует формирования значений уникального ключа и обязательных атрибутов кортежа);
- обновить: модификация данных – изменение значений отдельных атрибутов кортежей;
- извлечь: чтение данных;
- удалить: физическое или логическое удаление данных (кортежа или группы кортежей).
Структуризация данных в РМД существенно отличается от структуризации данных по версии CODASYL. В таблице 2.1. приведено соответствие этих двух вариантов структуризации.
Таблица 2.1. Сравнение структуризации данных в РМД и по версии CODASYL
| Термины версии CODASYL | Термины (и синонимы) РМД |
| Элемент данных | Атрибут (поле) |
| Агрегат | - |
| Запись (группа) | Кортеж (запись, строка) |
| Совокупность записей одного типа | Отношение (таблица) |
| Набор (групповое отношение) | - |
| База данных | База данных |

