




Первая задача при выполнении рассмотренного параллельного алгоритма суммирования состоит в необходимости передачи значений вектора x всем процессам параллельной программы. Конечно, для решения этой задачи можно воспользоваться рассмотренными ранее функциями парных операций передачи данных:
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
for (int i = 1; i < ProcNum; i++)
MPI_Send(&x, n, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
Однако такое решение будет крайне неэффективным, поскольку повторение операций передачи приводит к суммированию затрат (латентностей) на подготовку передаваемых сообщений. Кроме того, данная операция может быть выполнена за log2p итераций передачи данных.
Достижение эффективного выполнения операции передачи данных от одного процесса всем процессам программы (широковещательная рассылка данных) может быть обеспечено при помощи функции MPI:
int MPI_Bcast(void *buf, int count, MPI_Datatype type, int root,
MPI_Comm comm),
где
· buf, count, type — буфер памяти с отправляемым сообщением (для процесса с рангом 0) и для приема сообщений (для всех остальных процессов);
· root — ранг процесса, выполняющего рассылку данных;
· comm — коммуникатор, в рамках которого выполняется передача данных.
Функция MPI_Bcast осуществляет рассылку данных из буфера buf, содержащего count элементов типа type, с процесса, имеющего номер root, всем процессам, входящим в коммуникатор comm (см. рис. 5.1).
Следует отметить:
- функция MPI_Bcast определяет коллективную операцию, и, тем самым, при выполнении необходимых рассылок данных вызов функции MPI_Bcast должен быть осуществлен всеми процессами указываемого коммуникатора (см. далее пример программы);
- указываемый в функции MPI_Bcast буфер памяти имеет различное назначение у разных процессов: для процесса с рангом root, которым осуществляется рассылка данных, в этом буфере должно находиться рассылаемое сообщение, а для всех остальных процессов указываемый буфер предназначен для приема передаваемых данных;
- все коллективные операции "несовместимы" с парными операциями — так, например, принять широковещательное сообщение, отосланное с помощью MPI_Bcast, функцией MPI_Recv нельзя, для этого можно задействовать только MPI_Bcast.
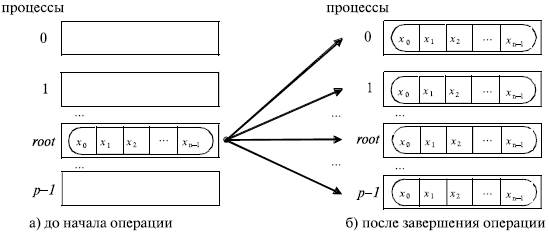
Рис. 4.1. Общая схема операции передачи данных от одного процесса всем процессам
Приведем программу для решения учебной задачи суммирования элементов вектора с использованием рассмотренной функции.
Программа 4.2. Параллельная программа суммирования числовых значений
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main(int argc, char* argv[]){
double x[100], TotalSum, ProcSum = 0.0;
int ProcRank, ProcNum, N=100, k, i1, i2;
MPI_Status Status;
// Инициализация
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&ProcNum);
MPI_Comm_rank(MPI_COMM_WORLD,&ProcRank);
// Подготовка данных
if (ProcRank == 0) DataInitialization(x,N);
// Рассылка данных на все процессы
MPI_Bcast(x, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
// Вычисление частичной суммы на каждом из процессов
// на каждом процессе суммируются элементы вектора x от i1 до i2
k = N / ProcNum;
i1 = k * ProcRank;
i2 = k * (ProcRank + 1);
if (ProcRank == ProcNum-1) i2 = N;
for (int i = i1; i < i2; i++)
ProcSum = ProcSum + x[i];
// Сборка частичных сумм на процессе с рангом 0
if (ProcRank == 0) {
TotalSum = ProcSum;
for (int i=1; i < ProcNum; i++) {
MPI_Recv(&ProcSum,1,MPI_DOUBLE,MPI_ANY_SOURCE,0, MPI_COMM_WORLD, &Status);
TotalSum = TotalSum + ProcSum;
}
}
else // Все процессы отсылают свои частичные суммы
MPI_Send(&ProcSum, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
// Вывод результата
if (ProcRank == 0)
printf("\nTotal Sum = %10.2f",TotalSum);
MPI_Finalize();
return 0;
}
Пример 4.2. (html, txt)
В приведенной программе функция DataInitialization осуществляет подготовку начальных данных. Необходимые данные могут быть введены с клавиатуры, прочитаны из файла или сгенерированы при помощи датчика случайных чисел – подготовка этой функции предоставляется как задание для самостоятельной разработки.
4.2. Передача данных от всех процессов одному процессу. Операция редукции
В рассмотренной программе суммирования числовых значений имеющаяся процедура сбора и последующего суммирования данных является примером часто выполняемой коллективной операции передачи данных от всех процессов одному процессу. В этой операции над собираемыми значениями осуществляется та или иная обработка данных (для подчеркивания последнего момента данная операция еще именуется операцией редукции данных). Как и ранее, реализация операции редукции при помощи обычных парных операций передачи данных является неэффективной и достаточно трудоемкой. Для наилучшего выполнения действий, связанных с редукцией данных, в MPI предусмотрена функция:
int MPI_Reduce(void *sendbuf, void *recvbuf, int count,
MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm),
где
· sendbuf — буфер памяти с отправляемым сообщением;
· recvbuf — буфер памяти для результирующего сообщения (только для процесса с рангом root);
· count — количество элементов в сообщениях;
· type — тип элементов сообщений;
· op — операция, которая должна быть выполнена над данными;
· root — ранг процесса, на котором должен быть получен результат;
· comm — коммуникатор, в рамках которого выполняется операция.
В качестве операций редукции данных могут быть использованы предопределенные в MPI операции – см. табл. 4.2.
Общая схема выполнения операции сбора и обработки данных на одном процессе показана на табл. 4.2. Элементы получаемого сообщения на процессе root представляют собой результаты обработки соответствующих элементов передаваемых процессами сообщений, т.е.:

где Ä есть операция, задаваемая при вызове функции MPI_Reduce (для пояснения на рис. 4.3 показан пример выполнения функции редукции данных).
Следует отметить:
· функция MPI_Reduce определяет коллективную операцию, и, тем самым, вызов функции должен быть выполнен всеми процессами указываемого коммуникатора. При этом все вызовы функции должны содержать одинаковые значения параметров count, type, op, root, comm;
· передача сообщений должна быть выполнена всеми процессами, результат операции будет получен только процессом с рангом root;
· выполнение операции редукции осуществляется над отдельными элементами передаваемых сообщений. Так, например, если сообщения содержат по два элемента данных и выполняется операция суммирования MPI_SUM, то результат также будет состоять из двух значений, первое из которых будет содержать сумму первых элементов всех отправленных сообщений, а второе значение будет равно сумме вторых элементов сообщений соответственно;
· не все сочетания типа данных type и операции op возможны, разрешенные сочетания перечислены в табл. 4.3.
Таблица 4.2.
Базовые (предопределенные) типы операций MPI для функций редукции данных
| Операции | Описание |
| MPI_MAX | Определение максимального значения |
| MPI_MIN | Определение минимального значения |
| MPI_SUM | Определение суммы значений |
| MPI_PROD | Определение произведения значений |
| MPI_LAND | Выполнение логической операции "И" над значениями сообщений |
| MPI_BAND | Выполнение битовой операции "И" над значениями сообщений |
| MPI_LOR | Выполнение логической операции "ИЛИ" над значениями сообщений |
| MPI_BOR | Выполнение битовой операции "ИЛИ" над значениями сообщений |
| MPI_LXOR | Выполнение логической операции исключающего "ИЛИ" над значениями сообщений |
| MPI_BXOR | Выполнение битовой операции исключающего "ИЛИ" над значениями сообщений |
| MPI_MAXLOC | Определение максимальных значений и их индексов |
| MPI_MINLOC | Определение минимальных значений и их индексов |
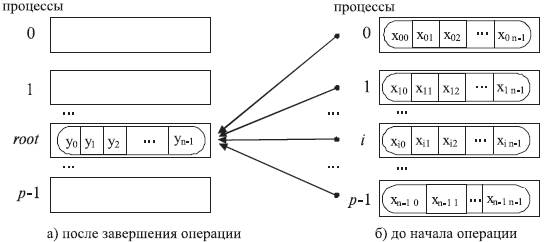
Рис. 4.2. Общая схема операции сбора и обработки на одном процессе данных от всех процессов
Таблица 4.3.
Разрешенные сочетания операции типа операнда в операции редукции
| Операции | Допустимый тип операндов для алгоритмического языка C |
| MPI_MAX, MPI_MIN, MPI_SUM, MPI_PROD | Целый, вещественный |
| MPI_LAND, MPI_LOR, MPI_LXOR | Целый |
| MPI_BAND, MPI_BOR, MPI_BXOR | Целый, байтовый |
| MPI_MINLOC, MPI_MAXLOC | Целый, вещественный |

Рис. 4.3. Пример выполнения операции редукции при суммировании пересылаемых данных для трех процессов (в каждом сообщении 4 элемента, сообщения собираются на процессе с рангом 2)
Применим полученные знания для переработки ранее рассмотренной программы суммирования: как можно увидеть, весь программный код ("Сборка частичных сумм на процессе с рангом 0"), может быть теперь заменен на вызов одной лишь функции MPI_Reduce:
// Сборка частичных сумм на процессе с рангом 0
MPI_Reduce(&ProcSum, &TotalSum, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
Лабораторная работа
В заданиях лабораторной работы 4 предлагается написать программу на языке C++ задачи, выданной преподавателем. Оттранслировать и сделать замеры времени реализации программы от объема исходных данных. Разработать параллельную MPI программу с использованием процедур MPICH 1.2.7, в том числе, процедур коллективного обмена.
Выполнить замеры времени реализации программы от числа процессоров и объема исходных данных. Построить графики показателей эффективности параллельных программ. Сделать выводы.
В состав отчета должны быть включены:
а) Титульный лист.
б) Распечатки откомпилированных текстов MPI-программ.
в) Скриншоты результатов выполнения программ.
г) Выводы по работе.

