




База данных - набор сведений, хранящихся некоторым упорядоченным способом.. Иными словами, база данных - это хранилище данных. Сами по себе базы данных не представляли бы интереса, если бы не было систем управления базами данных (СУБД).
База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью ЭВМ.
Система управления базами данных - это совокупность языковых и программных средств, которая осуществляет доступ к данным, позволяет их создавать, менять и удалять, обеспечивает безопасность данных и т.д. В общем СУБД - это система, позволяющая создавать базы данных и манипулировать сведениями из них. А осуществляет этот доступ к данным СУБД посредством специального языка - SQL.
Функции СУБД:
1) Непосредственное управление данными во внешней памяти
2) Управление буферами оперативной памяти
3) Управление транзакциями
4) Журнализация
5) Поддержка языков БД
2 Модели данных и их классификация.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Классификация
Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, ориентированные на формат документов - Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа.
Тезаурусные модели основаны на принципе организации словарей.
Дескриптпорные модели — В этих моделях каждому документу соответствовал дескриптор — описатель.
Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов.
3 Функциональные зависимости.
В процессе нормализации рассматриваются различные функциональные зависимости. Функциональные зависимости определяют не текущее состояние БД, а все возможные ее состояния. то есть они отражают те связи между атрибутами, которые присуши реальному объекту, моделируемые в БД.
Функциональная зависимость. Атрибут Y некоторого отношения функционально зависит от X (атрибуты могут быть составными), если в любой момент времени каждому значению X соответствует одно значение Y. Функциональная зависимость обозначается X →Y.
Избыточная функциональная зависимость - это зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Полная функциональная зависимость. Неключевой атрибут функционально полно зависит от составного ключа если он функционально зависит от всего ключа в целом, но не находится в функциональной зависимости от какого-либо из входящих в него атрибутов.
Транзитивная функциональная зависимость. Пусть X, Y, Z - три атрибута некоторого отношения. При этом X → Y и Y → Z, но обратное соответствие отсутствует, т.е. Z -/-> Y и Y -/-> X. Тогда Z транзитивно зависит от X.
Многозначная зависимость. Пусть X. Y, Z - три атрибута отношения R. В отношении R существует многозначная зависимость R.X -» R.Y только в том случае, если множество значений Y. соответствующее паре значений X и Z. зависит только от X и не зависит от Z.
В общем случае необходимо проводить нормализацию к пятой нормальной форме (5НФ). На практике зачастую оказывается достаточным приведение к третьей нормальной форме (ЗНФ).
4 Реляционная модель данных.
Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. По сути дела, в предыдущих двух разделах этой лекции мы рассматривали именно понятия и свойства структурной составляющей реляционной модели.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй - на классическом логическом аппарате исчисления предикатов первого порядка. Мы рассмотрим эти механизмы более подробно на следующей лекции, а пока лишь заметим, что основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Наконец, в целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Второе требование называется требованием целостности по ссылкам и является несколько более сложным.
5 Реляционная алгебра. Реляционная алгебра — формальная система манипулирования отношениями в реляционной модели данных. Выборка Операция выборки — унарный оператор, записываемый как σaθb(R) или σaθv(R), где:a, b — имена атрибутовθ — оператор сравнения из множества {<; ≤; =; ≥; >}v — константаR — отношение (в оригинале — relation, однако как видно из примера, подразумевается не столько взаимосвязь таблиц, сколько взаимосвязь/соотношение различных фактов в рядах этих таблиц).Выборка σaθb(R) (или σaθv(R)) выбирает все наборы значений R, для которых функция a θ b (или a θ v) будет истинна. Проекция Операция выборки — унарный оператор, записываемый как πa1,…,an(R) где a1,…,an — спиоск полей, подлежащих выборке. Результатом такой выборки будет набор последовательностей значений отношения R, в котором будут присутствовать только поля, перечисленные в списке a1,…,an с естественным уничтожением потенциально возникающих кортежей-дубликатов.
Объединение
Пересечение
Разность
Деление
Реляционное деление достаточно нетривиально описать, но на примере его смысл нагляден. В целом, из таблицы A берутся значения строк, для которых присутствуют все комбинации значений из таблицы B.
Соединение
Операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях и имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения такие атрибуты необходимо переименовать.
6 Этапы разработки базы данных.
При разработке БД можно выделить следующие этапы работы.
I этап. Постановка задачи.
На этом этапе формируется задание по созданию БД. В нем подробно описывается состав базы, назначение и цели ее создания, а также перечисляется, какие виды работ предполагается осуществлять в этой базе данных (отбор, дополнение, изменение данных, печать или вывод отчета и т. д).
II этап. Анализ объекта.
На этом этапе рассматривается, из каких объектов может состоять БД, каковы свойства этих объектов. После разбиения БД на отдельные объекты необходимо рассмотреть свойства каждого из этих объектов, или, другими словами, установить, какими параметрами описывается каждый объект. Все эти сведения можно располагать в виде отдельных записей и таблиц. Далее необходимо рассмотреть тип данных каждой отдельной единицы записи. Сведения о типах данных также следует занести в составляемую таблицу.
III этап. Синтез модели.
На этом этапе по проведенному выше анализу необходимо выбрать определенную модель БД. Далее рассматриваются достоинства и недостатки каждой модели и сопоставляются с требованиями и задачами создаваемой БД. После такого анализа выбирают ту модель, которая сможет максимально обеспечить реализацию поставленной задачи. После выбора модели необходимо нарисовать ее схему с указанием связей между таблицами или узлами.
IV этап. Выбор способов представления информации и программного инструментария.
V этап. Синтез компьютерной модели объекта.
Стадия 1. Запуск СУБД, создание нового файла базы данных или открытие созданной ранее базы.
Стадия 2. Создание исходной таблицы или таблиц.
При проектировании таблиц, рекомендуется руководствоваться следующими основными принципами:
1. Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
2. Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах, с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
3. Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля "Имя" и "Фамилия", а не общее поле "Имя").
4. База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Стадия 3. Создание экранных форм.
Первоначально необходимо указать таблицу, на базе которой будет создаваться форма. Ее можно создавать при помощи мастера форм, указав, какой вид она должна иметь, или самостоятельно. При создании формы можно указывать не все поля, которые содержит таблица, а только некоторые из них. Имя формы может совпадать с именем таблицы, на базе которой она создана. На основе одной таблицы можно создать несколько форм, которые могут отличаться видом или количеством используемых из данной таблицы полей. После создания форму необходимо сохранить. Созданную форму можно редактировать, изменяя местоположение, размеры и формат полей.
Стадия 4. Заполнение БД.
VI этап. Работа с созданной базой данных.
7 Концептуальное проектирование базы данных.
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам.
Чаще всего концептуальная модель базы данных включает в себя:
описание информационных объектов, или понятий предметной области и связей между ними.
описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
8 Целостность данных.
Це́лостность ба́зы да́нных (database integrity) — соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам. Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности (integrity constraint). Примеры правил: вес детали должен быть положительным; количество знаков в телефонном номере не должно превышать 25; возраст родителей не может быть меньше возраста их биологического ребёнка и т.д.
Задача аналитика и проектировщика базы данных — возможно более полно выявить все имеющиеся ограничения целостности и задать их в базе данных.
Целостность БД не гарантирует достоверности содержащейся в ней информации, но обеспечивает по крайней мере правдоподобность этой информации, отвергая заведомо невероятные, невозможные значения. Таким образом, не следует путать целостность БД с достоверностью БД. Достоверность (или истинность) есть соответствие фактов, хранящихся в базе данных, реальному миру. Очевидно, что для определения достоверности БД требуется обладание полными знаниями как о содержимом БД, так и о реальном мире. Для определения целостности БД требуется лишь обладание знаниями о содержимом БД и о заданных для неё правилах. Поэтому СУБД может (и должна) контролировать целостность БД, но принципиально не в состоянии контролировать достоверность БД. Контроль достоверности БД может быть возложен только на человека, да и то в ограниченных масштабах, поскольку в ряде случаев люди тоже не обладают полнотой знаний о реальном мире.
9 Критерии согласованности. Согласованность (Consistency). В классическом смысле это свойство означает, что транзакция может быть успешно завершена с фиксацией результатов своих операций только в том случае, когда действия операций не нарушают целостность базы данных, т.е. удовлетворяют набору ограничений целостности, определенных для этой базы данных. Это свойство расширяется тем, что во время выполнения транзакции разрешается устанавливать точки согласованности и явным образом проверять ограничения целостности. (С точки зрения автора, в контексте баз данных термины согласованность и целостность эквивалентны. Единственным критерием согласованности данных является их удовлетворение ограничениям целостности, т.е. база данных находится в согласованном состоянии тогда и только тогда, когда она находится в целостном состоянии.)
10 1-я нормальная форма. Первая нормальная форма (1NF)Основные критерии:Все строки должны быть различными.Все элементы внутри ячеек должны быть атомарными (не списками). Другими словами, элемент является атомарным, если его нельзя разделить на части, которые могут использовать в таблице независимо друг от друга.Пример не 1NF таблицы:
| Категория | Товары |
| Книги | Война и Мир, Азбука |
| Игрушки | Юла |
| Категория | Товары |
| Книги | Война и Мир |
| Книги | Азбука |
| Игрушки | Юла |
| Категория | Дата | Скидка | Товар |
| Книги | 10.10.2008 | 10% | PHP for dummies |
| Ноутбуки | 11.10.2008 | 20% | Acer |
| Книги | 10.10.2008 | 10% | Windows XP |
| Категория | Дата | Скидка |
| Книги | 10.10.2008 | 10% |
| Ноутбуки | 11.10.2008 | 20% |
| Книги | 10.10.2008 | 10% |
| Категория | Товар | |
| Книги | PHP for dummies | |
| Ноутбуки | Acer | |
| Книги | Windows XP |
| Имя шпиона | Государство |
| Джеймс Бонд | Великобритания |
| Ким Филби | СССР |
| Штирлиц | СССР |
| ID | Государство | ||
| 1 | Великобритания | ||
| 2 | СССР | ||
| Имя шпиона | Государство | ||
| Джеймс Бонд | 1 | ||
| Ким Филби | 2 | ||
| Штирлиц | 2 | ||
15 Нормальная форма Бойса-Кодда.
Нормальная форма Бойса-Кодда (англ. Boyce-Codd normal form; сокращённо BCNF) — одна из возможных нормальных форм отношения в реляционной модели данных.
Иногда нормальную форму Бойса-Кодда называют усиленной третьей нормальной формой, поскольку она во всех отношениях сильнее (строже) по сравнению с ранее определённой ЗНФ.
Названа в честь Рэя Бойса и Эдгара Кодда, хотя Кристофер Дейт указывает, что на самом деле строгое определение «третьей» нормальной формы, эквивалентное определению нормальной формы Бойса-Кодда, впервые было дано Иэном Хитом (англ. Ian Heath) в 1971 году, поэтому данную форму следовало бы называть «нормальной формой Хита».
Переменная отношения находится в BCNF тогда и только тогда, когда каждая её нетривиальная и неприводимая слева функциональная зависимость имеет в качестве своего детерминанта некоторый потенциальный ключ[1].
Менее формально, переменная отношения находится в нормальной форме Бойса-Кодда тогда и только тогда, когда детерминанты всех ее функциональных зависимостей являются потенциальными ключами.
Для определения BCNF следует понимать понятие функциональной зависимости атрибутов отношения.
Пусть R является переменной отношения, а X и Y — произвольными подмножествами множества атрибутов переменной отношения R. Y функционально зависимо от X тогда и только тогда, когда для любого допустимого значения переменной отношения R, если два кортежа переменной отношения R совпадают по значению X, они также совпадают и по значению Y. Подмножество X называют детерминантом, а Y — зависимой частью.
Функциональная зависимость тривиальна тогда и только тогда, когда ее правая (зависимая) часть является подмножеством ее левой части (детерминанта).
Ситуация, когда отношение будет находиться в 3NF, но не в BCNF, возникает, например, при условии, что отношение имеет два (или более) потенциальных ключа, которые являются составными и имеют общий атрибут. На практике такая ситуация встречается достаточно редко, для всех прочих отношений 3NF и BCNF эквивалентны.
16 Транзакции и свойства транзакций. Транза́кция (англ. transaction) — группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций.Различают последовательные (обычные), параллельные и распределённые транзакции. Распределённые транзакции подразумевают использование больше чем одной транзакционной системы и требуют намного более сложной логики (например, two-phase commit — двухфазный протокол фиксации транзакции). Также, в некоторых системах реализованы автономные транзакции, или под-транзакции, которые являются автономной частью родительской транзакции.
Существуют некоторые свойства, которыми должна обладать любая транзакция.
1 Атомарность (atomicity). Предполагает, что транзакция должна быть либо завершена, либо не выполнена вовсе.
2 Непротиворечивость, постоянство (consistency). После завершения транзакции система должна находиться в известном состоянии, т.е. транзакция не должна оставлять после себя следов.
3 Изолированность (isolation). Транзакция должна быть изолирована, т.е. не должна влиять на другие транзакции и зависеть от них.
4 Устойчивость, продолжительность, долговечность (durability). Если транзакция завершена, и цель её достигнута, то не может быть никаких веских причин для её отката.
17 Индивидуальный откат транзакций.
Для того, чтобы можно было выполнить по общему журналу индивидуальный откат транзакции, все записи в журнале от данной транзакции связываются в обратный списокСписок— письменный перечень, число, состав; документ, содержащий перечень каких-либо сведений; в переносном смысле— буквальное, точное воспроизведение, копия; рукописная копия древнего памятника письменности.. Началом списка для незакончившихся транзакций является запись о последнем изменении базы данных, произведенном данной транзакцией. Для закончившихся транзакций (индивидуальные откаты которых уже невозможны) началом списка является запись о конце транзакции, которая обязательно вытолкнута во внешнюю память журнала. Концом списка всегда служит первая запись об изменении базы данных, произведенном данной транзакцией. Обычно в каждой записи проставляется уникальный идентификатор транзакции, чтобы можно было восстановить прямой список записей об изменениях базы данных данной транзакцией.
Итак, индивидуальный откат транзакции (еще раз подчеркнем, что это возможно только для незакончившихся транзакций) выполняется следующим образом:
· Выбирается очередная запись из списка данной транзакции.
· Выполняется противоположная по смыслу операция: вместо операции INSERT выполняется соответствующая операция DELETE, вместо операции DELETE выполняется INSERT, и вместо прямой операции UPDATE обратная операция
· UPDATE, восстанавливающая предыдущее состояние объекта базы данных.
· Любая из этих обратных операций также журнализуются. Собственно для индивидуального отката это не нужно, но при выполнении индивидуального отката транзакции может произойти мягкий сбой, при восстановлении после которого потребуется откатить такую транзакцию, для которой не полностью выполнен индивидуальный откат.
· При успешном завершении отката в журнал заносится запись о конце транзакции. С точки зрения журнала такая транзакциия является зафиксированной.
18 Метод временных меток. Альтернативный метод сериализации транзакций, хорошо работающий в условиях редких конфликтов транзакций и не требующий построения графа ожидания транзакций основан на использовании временных меток. Основная идея метода состоит в следующем: если транзакция A началась раньше транзакции B, то система обеспечивает такой режим выполнения, как если бы A была целиком выполнена до начала B. Для этого каждой транзакции T предписывается временная метка t, соответствующая времени начала T. При выполнении операции над объектом r базы данных транзакция T помечает его своей временной меткой и типом операции (чтение или изменение). Перед выполнением операции над объектом r транзакция B выполняет следующие действия: · Проверяет, не закончилась ли транзакция A, пометившая этот объект. Если A закончилась, B помечает объект r своей временной меткой и выполняет операцию.· Если транзакция A не завершилась, то B проверяет конфликтность операций. Если операции неконфликтны, при объекте r остается или проставляется временная метка с меньшим значением (более ранняя), и транзакция B выполняет свою операцию.· Если операции B и A конфликтуют, то если t(A) > t(B) (т.е. транзакция A является более "молодой", чем B), то транзакция A откатывается и, получив новую временную метку, начинается заново. Транзакция B продолжает работу.· Если же t(A) < t(B) (A "старше" B), то транзакция B откатывается и, получив новую временную метку, начинается заново. Транзакция A продолжает работу.· В итоге система обеспечивает такую работу, при которой при возникновении конфликтов всегда откатывается более молодая транзакция (начавшаяся позже). Очевидным недостатком метода временных меток является то, что может откатиться более дорогая транзакция, начавшаяся позже более дешевой. К другим недостаткам метода временных меток относятся потенциально более частые откаты транзакций, чем в случае использования блокировок. Это связано с тем, что конфликтность транзакций определяется более грубо. 19 Блокировки и решение проблем параллелизма.
Термин параллелизм означает возможность одновременной обработки СУБД нескольких транзакций, запрашивающих одни и те же данные, причем в одно и то же время.
Основная идея блокировки заключается в том, что если для выполнения некоторой транзакции необходимо, чтобы какой-либо объект (как правило, это строка таблицы) не изменился без ведома этой транзакции, то этот объект блокируется. Доступ к заблокированному объекту со стороны других транзакций ограничивается. Следовательно, вызвавшая блокировку транзакция в состоянии выполнить необходимую обработку с учетом того, что обрабатываемый объект не будет самопроизвольно изменяться (с точки зрения данной транзакции) столько времени, сколько потребуется. Блокировки по-другому называют синхронизационными захватами.
Таким образом, использование протокола доступа к данным на основе блокировок разрешает часть проблем параллелизма, но возникает новая проблема – тупики.
20 Проблемы параллельной работы транзакций.
Каким образом транзакции различных пользователей могут мешать друг другу? Различают три основные проблемы параллелизма:
- Проблема потери результатов обновления.
- Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание).
- Проблема несовместимого анализа.
Рассмотрим подробно эти проблемы.
Рассмотрим две транзакции, A и B, запускающиеся в соответствии с некоторыми графиками. Пусть транзакции работают с некоторыми объектами базы данных, например со строками таблицы. Операцию чтение строки 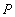 будем обозначать
будем обозначать  , где
, где 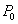 - прочитанное значение. Операцию записи значения
- прочитанное значение. Операцию записи значения 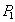 в строку будем обозначать
в строку будем обозначать 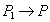 .
.
21 Преднамеренные блокировки.
Как видно из анализа поведения транзакций, при использовании протокола доступа к данным не решается проблема фантомов. Это происходит оттого, что были рассмотрены только блокировки на уровне строк. Можно рассматривать блокировки и других объектов базы данных:
- Блокировка самой базы данных.
- Блокировка файлов базы данных.
- Блокировка таблиц базы данных.
- Блокировка страниц (Единиц обмена с диском, обычно 2-16 Кб. На одной странице содержится несколько строк одной или нескольких таблиц).
- Блокировка отдельных строк таблиц.
- Блокировка отдельных полей.
Кроме того, можно блокировать индексы, заголовки таблиц или другие объекты.
Чем крупнее объект блокировки, тем меньше возможностей для параллельной работы. Достоинством блокировок крупных объектов является уменьшение накладных расходов системы и решение проблем, не решаемых с использованием блокировок менее крупных объектов. Например, использование монопольной блокировки на уровне таблицы, очевидно, решает проблему фантомов.
Современные СУБД, как правило, поддерживают минимальный уровень блокировки на уровне строк или страниц. (В старых версиях настольной СУБД Paradox поддерживалась блокировка на уровне отдельных полей.).
22 Виды восстановления данных.
Данные должны храниться в базе данных с избыточностью, позволяющей иметь информацию, по которой восстанавливается состояние базы данных на момент начала неудачной транзакции. Такую избыточность обычно обеспечивает журнал транзакций. Журнал транзакций содержит детали всех операций модификации данных в базе данных, в частности, старое и новое значение модифицированного объекта, системный номер транзакции, модифицировавшей объект и другая информация.
Восстановление базы данных может производиться в следующих случаях:
- Индивидуальный откат транзакции. Откат индивидуальной транзакции может быть инициирован либо самой транзакцией путем подачи команды ROLLBACK, либо системой. СУБД может инициировать откат транзакции в случае возникновения какой-либо ошибки в работе транзакции (например, деление на нуль) или если эта транзакция выбрана в качестве жертвы при разрешении тупика.
- Мягкий сбой системы (аварийный отказ программного обеспечения). Мягкий сбой характеризуется утратой оперативной памяти системы. При этом поражаются все выполняющиеся в момент сбоя транзакции, теряется содержимое всех буферов базы данных. Данные, хранящиеся на диске, остаются неповрежденными. Мягкий сбой может произойти, например, в результате аварийного отключения электрического питания или в результате неустранимого сбоя процессора.
- Жесткий сбой системы (аварийный отказ аппаратуры). Жесткий сбой характеризуется повреждением внешних носителей памяти. Жесткий сбой может произойти, например, в результате поломки головок дисковых накопителей.
Во всех трех случаях основой восстановления является избыточность данных, обеспечиваемая журналом транзакций.
23 Восстановление после мягкого и жесткого сбоев.
Во всех трех случаях основой восстановления является избыточность данных, обеспечиваемая журналом транзакций.
Как и страницы базы данных, данные из журнала транзакций не записываются сразу на диск, а предварительно буферизируются в оперативной памяти. Таким образом, система поддерживает два вида буферов - буферы страниц базы данных и буферы журнала транзакций.
Страницы базы данных, содержимое которых в буфере (в оперативной памяти) отличается от содержимого на диске, называются "грязными" (dirty) страницами. Система постоянно поддерживает список "грязных" страниц - dirty-список. Запись "грязных" страниц из буфера на диск называется выталкиванием страниц во внешнюю память. Очевидно, необходимо предусмотреть такие правила выталкивания буферов базы данных и буферов журнала транзакций, которые обеспечивали бы два требования:
- Максимальную скорость выполнения транзакций. Для этого необходимо выталкивать страницы как можно реже. В идеале, если оперативная память была бы бесконечной, и сбои никогда бы не происходили, наилучшим выходом была бы загрузка всей базы данных в оперативную память, работа с данными только в оперативной памяти, и запись измененных страниц на диск только в момент завершения работы всей системы.
- Гарантию, что при возникновении сбоя (любого типа), данные завершенных транзакций можно было бы восстановить, а данные незавершенных транзакций бесследно удалить, т.е. обеспечение восстановления последнего согласованного состояния базы данных. Для этого что-то выталкивать на диск все-таки необходимо, даже если мы обладали бы бесконечной оперативной памятью.
Таким образом, имеется две причины для периодического выталкивания страниц во внешнюю память - недостаток оперативной памяти и возможность сбоев.
24 Основные команды языка запросов SQL.
Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
SELECT (выбрать)
INSERT (вставить)
UPDATE (обновить)
DELETE (удалить)
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются:
CREATE DATABASE (создать базу данных)
CREATE TABLE (создать таблицу)
CREATE VIEW (создать виртуальную таблицу)
CREATE INDEX (создать индекс)
CREATE TRIGGER (создать триггер)
CREATE PROCEDURE (создать сохраненную процедуру)
ALTER DATABASE (модифицировать базу данных)
ALTER TABLE (модифицировать таблицу)
ALTER VIEW (модифицировать виртуальную таблицу)
ALTER INDEX (модифицировать индекс)
ALTER TRIGGER (модифицировать триггер)
ALTER PROCEDURE (модифицировать сохраненную процедуру)
DROP DATABASE (удалить базу данных)
DROP TABLE (удалить таблицу)
DROP VIEW (удалить виртуальную таблицу)
DROP INDEX (удалить индекс)
DROP TRIGGER (удалить триггер)
DROP PROCEDURE (удалить сохраненную процедуру)
25 SQL. Группировка и вычисления в запросах, соединения.
Группировку и вычисления, сами знаете если лабы делали…
| SELECT rkz.nazv, rkz.litr, ts.mag, ts.tsena FROM ts,rkz WHERE rkz.nazv=ts.nazv |
Здесь:
rkz.nazv, rkz.litr - поля nazv и litr из таблицы rkz;
ts.mag, ts.tsena - поля mag и tsena из таблицы ts;
WHERE rkz.nazv=ts.nazv - условие связывания строк таблиц - равенство значений поля nazv в обеих таблицах.
26 SQL. Представления. Хранимые процедуры и функции. Курсоры.
Представление - это фактически запрос, который выполняется всякий раз, когда представление становится темой команды. Вывод запроса при этом в каждый момент становится содержанием представления.
| КОМАНДА CREATE VIEW: |
| CREATE VIEW Londonstaff |
| AS SELECT * |
| FROM Salespeople |
| WHERE city = 'London'; |
Хранимые процедуры позволяют объединить последовательность запросов и сохранить их на сервере. Это очень удобный инструмент, и сейчас вы в этом убедитесь. Начнем с синтаксиса:
| CREATE PROCEDURE имя_процедуры (параметры) |
| begin |
| операторы |
| end |
Курсор — ссылка на контекстную область памяти[источник не указан 259 дней]. В некоторых реализациях информационно-логического языка SQL (Oracle, Microsoft SQL Server) — получаемый при выполнении запроса результирующий набор и связанный с ним указатель текущей записи.
В PL/SQL поддерживаются два типа курсоров: явные и неявные. Явный курсор объявляется разработчиком, а неявный курсор не требует объявления.
Курсор может возвращать одну строку, несколько строк или ни одной строки. Для запросов, возвращающих более одной строки, можно использовать только явный курсор. Для повторного создания результирующего набора для других значений параметров курсор следует закрыть, а затем повторно открыть.
Курсор может быть объявлен в секциях объявлений любого блока PL/SQL, подпрограммы или пакета.
27 Способы организации архитектуры баз данных.
Поскольку есть разные производители, и разные СУБД, существует разнообразные архитектуры.
1. Однобазовая архитектура – применяется в больших СУБД (Oracle и т.д.). преимущество такой БД – управление и контролирование БД происходит с одного сервера. Недостаток в том, что с течением времени, БД становится все больше и больше. Усложняются проблемы с резервным копированием и т.д.
2. Многобазовая архитектура – основное преимущество такой архитектуры в том, что упрощается проектирование. Для каждого приложения можно фактически создать свою базу данных. СУБД как программное обеспечение может управлять большим набором баз данных – InterBase, SQL-server – десятки тысяч СУБД могут поддерживаться одним сервером, а баз как файлов м.б. много – главное, чтобы сервер их видел. Недостатком таких СУБД является то, что при записи данных организаций в разные БД, считать данные из них представляет проблему.
3. Каталоговая архитектура – Desktop’овские СУБД. Базой данных является отдельный каталог: таблицы – отдельный файл, индекс – отдельный файл. Все расположено в отдельном каталоге, которых может быть много. Есть интересные решения в MS Access в одном файле таблицы, индексы, запросы находятся в одном файле. Есть свои плюсы и минусы. Трудно настраивать ПО постороннему – он должен сидеть в этой БД. Не каждая организация даст копию своей базы данных.
28 Физические модели хранения данных в СУБД.
Физическая модель БД определяет способ размещения данных на носителях (устройствах внешней памяти), а также способ и средства организации эффективного доступа к ним. Поскольку СУБД функционирует в составе и под управлением операционной системы, то организация хранения данных и доступа к ним зависит от принципов и методов управления данными операционной системы.
К вопросам организации данных относятся:
· выбор типа записи – единицы обмена в операциях ввода-вывода;
· выбор способа размещения записей в файле и, возможно, метода оптимизации размещения;
· выбор способа адресации и метода доступа к записям.
Стадия физического проектирования БД в общем случае включает:
· выбор способа организации БД;
· разработку спецификации внутренней схемы;
· описание отображения концептуальной схемы во внутреннюю.
В отличие от ранних СУБД, многие современные системы не предоставляют разработчику какого-либо выбора на этой стадии. Реально к вопросам проектирования физической модели можно отнести:
· выбор схемы размещения данных (разделение по файлам или тип RAID-массива);
· определение числа и типа индексов (например, кластеризованный или некластеризованный в случае MS SQL Server).
Способ хранения БД определяется механизмами СУБД автоматически по умолчанию на основе спецификаций концептуальной схемы БД, и внутренняя схема в явном виде в таких системах не используется. Внешние схемы БД обычно конструируются на стадии разработки приложений.
29 Защита информации в базах данных.
В современных СУБД поддерживается один из двух наиболее общих подходов к вопросу обеспечения безопасности данных: избирательный подход и обязательный подход. В обоих подходах единицей данных или «объектом данных», для которых должна быть создана система безопасности, может быть как вся база данных целиком, так и любой объект внутри базы данных.
На самом элементарном уровне концепции обеспечения безопасности баз данных исключительно просты. Необходимо поддерживать два фундаментальных принципа: проверку полномочий и проверку подлинности (аутентификацию).
Проверка полномочий основана на том, что каждому пользователю или процессу информационной системы соответствует набор действий, которые он может выполнять по отношению к определенным объектам. Проверка подлинности означает достоверное подтверждение того, что пользователь или процесс, пытающийся выполнить санкционированное действие, действительно тот, за кого он себя выдает.
Система назначения полномочий имеет в некотором роде иерархический характер. Самыми высокими правами и полномочиями обладает системный администратор или администратор сервера БД. Традиционно только этот тип пользователей может создавать других пользователей и наделять их определенными полномочиями.
СУБД в своих системных каталогах хранит как описание самих пользователей, так и описание их привилегий по отношению ко всем объектам.
Далее схема предоставления полномочий строится по следующему принципу. Каждый объект в БД имеет владельца — пользователя, который создал данный объект. Владелец объекта обладает всеми правами-полномочиями на данный объект, в том числе он имеет право предоставлять другим пользователям полномочия по работе с данным объектом или забирать у пользователей ранее предоставленные полномочия.
В ряде СУБД вводится следующий уровень иерархии пользователей — это администратор БД. В этих СУБД один сервер может управлять множеством СУБД (например, MS SQL Server, Sybase).
В стандарте SQL определены два оператора: GRANT и REVOKE соответственно предоставления и отмены привилегий.
30 Индексирование. Триггеры.
Индекс - структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей.
Индекс в базе данных аналогичен предметному указателю в книге. Это — вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
- Первичный индекс.
Файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи.
- Индекс кластеризации.
Файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
- Вторичный индекс.
Индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.
Триггеры являются одной из разновидностей хранимых процедур. Их исполнение происходит при выполнении для таблицы какого-либо оператора языка манипулирования данными (DML). Триггеры используются для проверки целостности данных, а также для отката транзакций.
Типы триггеров
В SQL Server существует два параметра, определяющих поведение триггеров:
- AFTER. Триггер выполняется после успешного выполнения вызвавших его команд. Если же команды по какой-либо причине не могут быть успешно завершены, триггер не выполняется. Следует отметить, что изменения данных в результате выполнения запроса пользователя и выполнение триггера осуществляется в теле одной транзакции: если произойдет откат триггера, то будут отклонены и пользовательские изменения. Можно определить несколько AFTER-триггеров для каждой операции (INSERT, UPDATE, DELETE). Если для таблицы предусмотрено выполнение нескольких AFTER-триггеров, то с помощью системной хранимой процедуры sp_settriggerorder можно указать, какой из них будет выполняться первым, а какой последним. По умолчанию в SQL Server все триггеры являются AFTER-триггерами.
- INSTEAD OF. Триггер вызывается вместо выполнения команд. В отличие от AFTER-триггера INSTEAD OF- триггер может быть определен как для таблицы, так и для просмотра. Для каждой операции INSERT, UPDATE, DELETE можно определить только один INSTEAD OF-триггер.
Триггеры различают по типу команд, на которые они реагируют.
Существует три типа триггеров:
- INSERT TRIGGER – запускаются при попытке вставки данных с помощью команды INSERT.
- UPDATE TRIGGER – запускаются при попытке изменения данных с помощью команды UPDATE.
- DELETE TRIGGER – запускаются при попытке удаления данных с помощью команды DELETE.

