




ƒругою стад≥Їю статистичного досл≥дженн€ Ї статистичне зведенн€ ≥ групуванн€, оск≥льки п≥сл€ збору даних, ми повинн≥ њх звести, згрупувати дл€ обробки.
І «веденн€ Ц це комплекс посл≥довних операц≥й по узагальненню конкретних поодиноких фактор≥в, €к≥ утворюють сукупн≥сть, дл€ ви€вленн€ типових рис ≥ законом≥рностей, що належать досл≥джуваному €вищу в ц≥лому.
- «веденн€ може бути просте ≥ складне.
ѕросте зведенн€ Ц це простий п≥драхунок п≥дсумк≥в первинних статистичних даних.
—кладне зведенн€ передбачаЇ групуванн€, види групувальноњ ознаки, встановленн€ меж групуванн€, п≥драхунок групових ≥ узагальнюючих п≥дсумк≥в, а також викладенн€ результат≥в зведенн€ у вигл€д≥ таблиць чи граф≥к≥в.
“обто, зареЇстрован≥ у процес≥ масового статистичного спостереженн€ значенн€ ознак в≥дбивають увесь д≥апазон обТЇктивно ≥снуючоњ в сукупност≥ вар≥ац≥њ. ” розмањтт≥ поодиноких в≥домостей губитьс€ загальне, у не≥стотному ≥ випадковому Ч законом≥рне. ѕерех≥д в≥д одиничного до загального в≥дбуваЇтьс€ завд€ки зведенню.
—уть статистичного зведенн€ пол€гаЇ в тому, що матер≥али спостереженн€ класиф≥кують та агрегують. ≈лементи сукупност≥ за певними ознаками обТЇднують у групи, класи, типи, а ≥нформац≥ю про них агрегують €к у межах груп, так ≥ в ц≥лому по сукупност≥. ќсновне завданн€ зведенн€ Ч ви€вити типов≥ риси та законом≥рност≥ масових €вищ чи процес≥в.
«веденн€ Ї основою подальшого анал≥зу статистичноњ ≥нформац≥њ. «а зведеними даними обчислюють узагальнююч≥ показники, виконують пор≥вн€льний анал≥з, а також анал≥з причин групових в≥дм≥нностей, вивчають взаЇмозвТ€зки м≥ж ознаками.
—кладов≥ статистичного зведенн€ так≥:
1) розробка програми систематизац≥њ та групуванн€ даних;
2) обірунтуванн€ системи показник≥в дл€ характеристики груп ≥ сукупност≥ в ц≥лому;
3) проектуванн€ макет≥в таблиць, в €ких подаютьс€ результати зведенн€;
4) визначенн€ технолог≥чних схем обробки ≥нформац≥њ, програмного забезпеченн€;
5) п≥дготовка даних до обробки на компТютер≥, формуванн€ автоматизованих банк≥в даних;
6) безпосереднЇ зведенн€, узагальненн€, розрахунок показник≥в.
ѕрограма систематизац≥њ та групуванн€ даних передбачаЇ виб≥р групувальних ознак ≥ правил формуванн€ груп. –озробка програми, €к ≥ обірунтуванн€ системи показник≥в, залежить в≥д мети досл≥дженн€, сут≥ €вища, €ке вивчаЇтьс€, особливостей сукупност≥, ступен€ вар≥ац≥њ групувальних ознак.
Ќайчаст≥ше вс≥ зведенн€ ≥ групуванн€ оформлюютьс€ у вигл€д≥ статистичних таблиць.
І —татистична таблиц€ Ц це форма найб≥льш рац≥онального, наочного ≥ систематизованого викладу числових результат≥в зведенн€ ≥ обробки статистичних матер≥ал≥в
—татистичну таблицю можна пор≥вн€ти з реченн€м: вона складаЇтьс€ з п≥дмета ≥ присудка.
І ѕ≥дметом статистичноњ таблиц≥ називаЇтьс€ статистична сукупн≥сть або њ частина, €ка характеризуЇтьс€ числовими показниками.
І ѕрисудком називаЇтьс€ та частина, що вм≥щаЇ показники, що характеризують досл≥джувану сукупн≥сть та њњ частини (тобто п≥дмет)
—татистична таблиц€ маЇ три заголовки: один зовн≥шн≥й ≥ два внутр≥шн≥х:
|
|
|
 √рупуванн€ банк≥в ”крањни за величиною статутного фонду на 1 березн€ 1999 року. √рупуванн€ банк≥в ”крањни за величиною статутного фонду на 1 березн€ 1999 року.
| |||||||
 ѕрисудок
ѕ≥дмет ѕрисудок
ѕ≥дмет
| ≥льк≥сть | ѕитома вага | ≤нш≥ ознаки | ||||
| 5,0 Ц 7,5 | |||||||
| 7,5 Ц 10,0 | |||||||
| 10,0 Ц 12,5 | |||||||
| 12,5 Ц 15,0 | |||||||

|
ѕри оформленн≥ курсовоњ сл≥д пам'€тати, що при поданн≥ таблиць в правому кутку пишемо: "“аблиц€ Е(номер)Е", по центру Ц заголовок таблиц≥. ѕосиланн€ на таблицю в текст≥ позначаЇтьс€ словом "табл." + номер таблиц≥. ѕри ≥снуванн≥ великоњ к≥лькост≥ розд≥л≥в, при формуванн≥ номеру таблиц≥ вказуЇмо номер таблиц≥, пот≥м через крапку Ц номер розд≥лу, напр. "“аблиц€ 1.1"
“аблиц≥ можуть бути простими, груповими ≥ комб≥нац≥йними.
ѕростими називаютьс€ так≥ таблиц≥, в п≥дмет≥ €ких м≥ститьс€ перел≥к об'Їкт≥в, адм≥н≥стративних ≥ територ≥альних одиниць або р€д пер≥од≥в, дат, охарактеризованих числовими показниками. ѕрост≥ таблиц≥ Ї найб≥льш поширеними.
√рупов≥ таблиц≥ Ц це таблиц≥, п≥дмет €ких м≥стить одиниц≥ досл≥джуваного об'Їкту, згрупованих за певною суттЇвою ознакою.
омб≥нац≥йн≥ таблиц≥ Ц це таблиц≥, в €ких п≥дмет побудований за двома ≥ б≥льше ознаками.
ѕриклад комб≥нац≥йноњ таблиц≥.
| √рупуванн€ банк≥в ”крањни за величиною статутного фонду на 1 березн€ 1999 року. | ||||||
| –озм≥р статутного фонду | ѕрибутков≥сть атив≥в | ≥льк≥сть | ѕитома вага | ≤нш≥ ознаки | ||
| 5,0 Ц 7,5 | 1,5 Ц 2,0 2,0 Ц 2,5 2,5 Ц 3,0 | |||||
| –азом | ||||||
| 7,5 Ц 10,0 | 1,5 Ц 2,0 2,0 Ц 2,5 2,5 Ц 3,0 | |||||
| –азом | ||||||
| ¬ ц≥лому по сукупност≥ |
ѕравила складанн€ таблиць:
1) “аблиц€ повинна бути компактною ≥ мати т≥льки т≥ вих≥дн≥ дан≥, €к≥ безпосередньо в≥дображають досл≥джуване €вище.
2) «аголовок таблиц≥, назви граф ≥ строчок повинн≥ бути зрозум≥лими, ч≥ткими, лакон≥чними ≥ зак≥нченими.
3) ¬ графах допускаютьс€ скороченн€ т≥льки при необх≥дност≥.
4) “аблиц€ повинна бути замкнута ≥ мати п≥дсумкову строку. ÷€ п≥дсумкова строка може знаходитись на початку таблиц≥.
5) ѕоказники, що характеризують один одного, повинн≥ м≥ститис€ поруч.
6) √рафи нумерують арабськими цифрами, п≥дмет Ц латинськими л≥терами.
7) якщо €вище повн≥стю в≥дсутнЇ, то в кл≥тинки, де маЇ бути його к≥льк≥сне значенн€ ставитьс€ тире. якщо досл≥дник не може знайти в≥домост≥ про певне €вище, то в кл≥тинку ставитьс€ три крапки, або "н.в." Ц немаЇ в≥домостей. якщо дана кл≥тинка не заповнюЇтьс€, то в нењ ставитьс€ хрестик чи з≥рочка.
«а видами групуванн€ таблиц≥ можуть бути типолог≥чн≥, структурн≥ ≥ анал≥тичн≥ (див. лекц≥ю щодо вид≥в групуванн€).
ќтже, результати статистичного зведенн€ подаютьс€ у форм≥ статистичних таблиць, макети €ких розроблюютьс€ разом з програмою обробки даних.
|
|
|
ћакет статистичноњ таблиц≥ Ч це комб≥нац≥€ горизонтальних р€дк≥в ≥ вертикальних граф, на перетин≥ €ких утворюютьс€ кл≥тинки. Ћ≥в≥ б≥чн≥ та верхн≥ кл≥тинки призначен≥ дл€ словесних заголовк≥в Ч перел≥ку складових сукупност≥ та системи показник≥в, решта Ч дл€ числових даних. ќсновний зм≥ст таблиц≥ розкриваЇ њњ назва (рис. 3.1).
“аблиц€ 3
Ќј«¬ј “јЅЋ»÷≤ (що, де, коли)
| «м≥ст р€дк≥в (п≥дмет) | ¬ерхн≥ заголовки (присудок) | ||||
| ј | ... | ||||
| Ѕ≥чн≥ заголовки | |||||
| ѕ≥дсумковий р€док |
–ис. 3.1. ћакет статистичноњ таблиц≥
Ќа практиц≥ використовуютьс€ р≥зн≥ технолог≥чн≥ схеми компТютерноњ обробки первинних даних. —п≥льними дл€ вс≥х Ї дв≥ операц≥њ: кодуванн€ даних ≥ перенесенн€ њх ≥з документ≥в на техн≥чн≥ нос≥њ ≥нформац≥њ, наприклад на магн≥тн≥ диски.
оди Ч це умовн≥ ≥дентиф≥катори ознак. ÷ентрал≥зовано розроблен≥ Їдин≥ класиф≥катори, оформлен≥ у вигл€д≥ словник≥в, забезпечують однозначн≥сть код≥в. —формован≥ автоматизован≥ банки даних уможливлюють багаторазове використанн€ ≥нформац≥њ, при цьому поглиблюЇтьс€ анал≥з, зменшуЇтьс€ к≥льк≥сть помилок.
«а формою обробки даних зведенн€ бувають централ≥зованими та децентрал≥зованими.
” статистичн≥й практиц≥ ≥нформац≥€ обробл€Їтьс€ переважно децентрал≥зовано. “ак, у раз≥ обробки статистичноњ зв≥тност≥ зведенн€ зд≥йснюЇтьс€ в≥д нижчоњ до вищоњ ланки управл≥нн€: зв≥ти п≥дприЇмств звод€тьс€ рег≥ональними статистичними органами, п≥дсумки по рег≥онах передаютьс€ в ƒержкомстат, де узагальнюютьс€ в ц≥лому по крањн≥. ’арактерн≥ класиф≥кац≥йн≥ позиц≥њ, Ђрозр≥зиї зведенн€ так≥: територ≥альна ознака (область, м≥сто, район), п≥дпор€дкован≥сть (м≥н≥стерство, в≥домство), галуз≥ господарськоњ д≥€льност≥, форми власност≥.
ћатер≥али перепис≥в, одноразових статистичних обстежень, соц≥олог≥чних опитувань надход€ть до Їдиного центру, де й обробл€ютьс€. “ака форма зведенн€ називаЇтьс€ централ≥зованою.
—татистичне групуванн€
ќдним ≥з найважлив≥ших метод≥в статистики Ї групуванн€.
І ѕ≥д групуванн€м в статистиц≥ розум≥ють розпод≥л одиниць статистичноњ сукупност≥ на групи, однор≥дн≥ в €кому-небудь суттЇвому в≥дношенн≥.
¬оно Ї €краз той метод ≥ та стад≥€, пропустивши €ку ми не можемо застосовувати ≥нш≥ методи. “ому в статистиц≥ групуванн€ використовуЇтьс€ дл€ вир≥шенн€ р≥зних завдань, таких €к, наприклад:
- визначенн€ ≥ вивченн€ структури ≥ структурних зрушень сукупност≥;
- ви€вленн€ соц≥ально-економ≥чних тип≥в €вищ ≥ процес≥в;
- ви€вленн€ ≥ характеризуванн€ зв'€зк≥в ≥ залежностей м≥ж €вищами та њх ознаками (таке досл≥дженн€ маЇ назву анал≥тичноњ функц≥њ групуванн€).
¬≥дпов≥дно до цих трьох функц≥й розр≥зн€ють р≥зн≥ види групуванн€: структурн≥, типолог≥чн≥ ≥ анал≥тичн≥.
√рупуванн€, в результат≥ €кого вид≥л€ють однор≥дн≥ групи або типи €вищ, €к вираз конкретного сусп≥льного процесу називаютьс€ типолог≥чними. ѕрикладом типолог≥чних групувань може бути под≥л п≥дприЇмств за характеристикою вид≥в власност≥, групуванн€ крањн за економ≥чним розвитком.
—труктурними групуванн€ми називаютьс€ групуванн€, €к≥ характеризують розпод≥л одиниць однотипноњ сукупност≥ за будь-€кою ознакою. “иполог≥чн≥ ≥ структурн≥ групуванн€ дуже близьк≥ один до одного: типолог≥чн≥ групуванн€ вид≥л€ють сам≥ типи, а структурн≥ Ц вказують питому вагу окремих тип≥в у загальн≥й мас≥.
јнал≥тичн≥ групуванн€ Ц це групуванн€, €к≥ визначають взаЇмозв'€зок м≥ж р≥зними ознаками одиниць статистичноњ сукупност≥. «а допомогою такого групуванн€ можна ви€вити певн≥ взаЇмозв'€зки м≥ж факторними ≥ результативними ознаками. Ќаприклад, залежн≥сть м≥ж р≥внем квал≥ф≥кац≥њ прац≥вника та його зароб≥тною працею. јнал≥тичн≥ групуванн€ Ї дуже складними ≥ дл€ того, щоб зрозум≥ти, €к вони будуютьс€, необх≥дно ч≥тко вид≥лити факторн≥ ≥ результативн≥ ознаки в досл≥джуваному €вищ≥.
|
|
|
ћожлив≥ зм≥шанн€ цих тип≥в групуванн€.
√рупуванн€ можуть бути прост≥ ≥ комб≥нован≥.
ѕрост≥ групуванн€ Ц це так≥ групуванн€, €к≥ зд≥йснен≥ на п≥дстав≥ одн≥Їњ ознаки.
омб≥нован≥ групуванн€ Ц це групуванн€, €к≥ зд≥йснен≥ за двома ≥ б≥льше ознаками.
омб≥нац≥йн≥ групуванн€ дають можлив≥сть комплексного характеризуванн€ досл≥джуваного €вища чи процесу.
ƒл€ того, щоб зробити групуванн€ за к≥льк≥сною ознакою, необх≥дно визначитис€ з к≥льк≥стю груп та з ≥нтервалом групуванн€.
≥льк≥сть груп визначаЇтьс€ математичними методами. ¬она маЇ б≥ти н≥ занадто малою, н≥ занадто великою, вони мають не заважати проанал≥зувати к≥нцевий результат.
¬еличина ≥нтервалу  , де xmax Ц максимальне значенн€, xmin Ц м≥н≥мальне значенн€, n Ц к≥льк≥сть груп сукупност≥.
, де xmax Ц максимальне значенн€, xmin Ц м≥н≥мальне значенн€, n Ц к≥льк≥сть груп сукупност≥.
≤нтервали можуть бути в≥дкрит≥ ≥ закрит≥, р≥вн≥ ≥ нер≥вн≥.
–≥вн≥ ≥нтервали Ц ≥нтервали з однаковою р≥зницею м≥ж верхньою ≥ нижньою границ€ми кожного пром≥жку.
Ќер≥вн≥ ≥нтервали Ц ≥нтервали з р≥зними р≥зниц€ми м≥ж верхньою ≥ нижньою границ€ми в р≥зних пром≥жках.
¬≥дкритий ≥нтервал Ц ≥нтервал з в≥дсутньою одн≥Їю ≥з границь (наприклад, б≥льше 100, менше 1).
«акрит≥ ≥нтервали Ц ≥нтервали, в €ких присутн≥ вс≥ границ≥.
ќсобливим видом групуванн€ Ї класиф≥кац≥€.
І ласиф≥кац≥Їю називаЇтьс€ систематизований розпод≥л €вищ ≥ процес≥в (об'Їкт≥в) на визначен≥ групи, класи, розр€ди на п≥дстав≥ њх под≥бност≥ ≥ розб≥жност≥.
ласиф≥кац≥њ в≥др≥зн€ютьс€ в≥д групувань тим, що групувальною основою класиф≥кац≥њ Ї €к≥сна ознака, вони б≥льш ст≥йк≥, стал≥ ≥ стандартн≥.
ѕод≥л сукупностей на групи, однор≥дн≥ в тому чи ≥ншому розум≥нн≥, повТ€заний з такими д≥€ми, €к систематизац≥€, типолог≥€, класиф≥кац≥€, групуванн€. “радиц≥йно зазначений под≥л виконують за такою схемою: ≥з множини ознак, €к≥ описують €вище, добирають розмежувальн≥, а пот≥м сукупн≥сть под≥л€ють на групи та п≥дгрупи в≥дпов≥дно до значень цих ознак.
√оловний принцип будь-€кого под≥лу ірунтуЇтьс€ на двох положенн€х:
1) в один клас, групу обТЇднуютьс€ елементи певною м≥рою под≥бн≥ м≥ж собою;
2) ступ≥нь под≥бност≥ м≥ж елементами, €к≥ належать до одного класу, значно вищий, н≥ж м≥ж елементами, що належать до р≥зних клас≥в.
” кожному конкретному досл≥дженн≥ вир≥шуютьс€ три питанн€:
1) що вз€ти за основу групуванн€;
2) ск≥льки груп, позиц≥й необх≥дно виокремити;
3) €к розмежувати групи.
ќсновою групуванн€ може бути будь-€ка атрибутивна чи к≥льк≥cна ознака, що маЇ градац≥њ. “аку ознаку називають групувальною. «алежно в≥д складност≥ масового €вища (процесу) та мети досл≥дженн€ групувальних ознак може бути одна, дв≥ й б≥льше.
” статистичн≥й практиц≥ часто вдаютьс€ до розбитт€ сукупностей за атрибутивними ознаками Ч класиф≥кац≥њ та номенклатури. ѓх розробл€ють м≥жнародн≥ й нац≥ональн≥ статистичн≥ органи та рекомендують €к статистичний стандарт. «деб≥льшого йдетьс€ про багатоступеневу класиф≥кац≥ю з докладною номенклатурою груп ≥ п≥дгруп, ≥з ч≥тко визначеними вимогами та умовами в≥днесенн€ елемент≥в сукупност≥ до т≥Їњ чи ≥ншоњ групи.
” м≥жнародн≥й статистиц≥ в≥дома галузева класиф≥кац≥€ вид≥в економ≥чноњ д≥€льност≥, стандартна класиф≥кац≥€ зан€ть, стандарт≠на торговельна класиф≥кац≥€. –≥зновидом класиф≥кац≥њ Ї товарн≥ номенклатури, наприклад Ѕрюссельська митна номенклатура.
ожн≥й класиф≥кац≥йн≥й позиц≥њ надаЇтьс€ код (шифр), €кий зам≥нюЇ њњ назву ≥ Ї пост≥йним засобом ≥дентиф≥кац≥њ п≥д час передаванн€ ≥нформац≥њ по каналах звТ€зку, компТютерноњ обробки тощо. “ак, зг≥дно з м≥жнародним стандартом галузевоњ класиф≥кац≥њ, розробленоњ статистичною ком≥с≥Їю ќќЌ, код виду економ≥чноњ д≥€льност≥ складаЇтьс€ з чотирьох цифр. Ќаприклад, 15 5 2 означаЇ:
|
|
|
15 Ч код галуз≥ обробноњ промисловост≥ Ђ¬иробництво продукт≥в харчуванн€ та напоњвї;
5 Ч виробництво напоњв;
2 Ч виробництво вин.
ожна класиф≥кац≥€ Ї сталою, забезпечуючи пор≥вн€нн≥сть даних у простор≥ та час≥.
ѕор€д з класиф≥кац≥Їю дл€ висв≥тленн€ певних аспект≥в конкретного досл≥дженн€ використовують групуванн€, на €ке покладаютьс€ так≥ анал≥тичн≥ функц≥њ:
1) вивченн€ структури та структурних зрушень;
2) визначенн€ тип≥в соц≥ально-економ≥чних €вищ, виокремленн€ однор≥дних груп ≥ п≥дгруп;
3) ви€вленн€ взаЇмозвТ€зк≥в м≥ж ознаками.
«г≥дно з цими функц≥€ми розр≥зн€ють три види групувань: структурне, типолог≥чне, анал≥тичне.
—труктурне групуванн€ характеризуЇ склад однор≥дноњ сукупност≥ за певними ознаками. Ќаприклад, склад населенн€ рег≥ону за м≥сцем проживанн€ (табл. 3.1). «а даними таблиц≥ з 5,3 млн населенн€ рег≥ону в м≥стах проживаЇ 3,5 або 2/3 загальноњ к≥лькост≥. Ќа одного с≥льського жител€ припадають двоЇ м≥ських. ожна група характеризуЇтьс€ також к≥льк≥стю та часткою населенн€ працездатного в≥ку, ≥ це поглиблюЇ анал≥з структури.
“аблиц€ 3.1
ѕќƒ≤Ћ Ќј—≈Ћ≈ЌЌя –≈√≤ќЌ”, млн ос≥б,
«ј ћ≤—÷≈ћ ѕ–ќ∆»¬јЌЌя
| ћ≥сце проживанн€ | ”се населенн€ | ” тому числ≥ у працездатному в≥ц≥ |
| ћ≥ста | 3,5 | 2,1 |
| —≥льська м≥сцев≥сть | 1,8 | 0,9 |
| –азом | 5,3 | 3,0 |
–≥зновидом структурних групувань Ї р€ди розпод≥лу (див. розд. 5).
“иполог≥чне групуванн€ Ч це под≥л €к≥сно неоднор≥дноњ сукупност≥ на класи, соц≥ально-економ≥чн≥ типи, однор≥дн≥ групи. ќсновне завданн€ такого групуванн€ Ч ≥дентиф≥кац≥€ тип≥в. ¬иб≥р групувальноњ ознаки та к≥льк≥сних м≥жгрупових меж ірунтуЇтьс€ на всеб≥чному теоретичному анал≥з≥ сут≥ €вища, його характерних рис та особливостей формуванн€ в конкретних умовах часу та простору.
“ак, в умовах перех≥дноњ економ≥ки в крањнах —х≥дноњ ™вропи зубож≥нн€ населенн€ перетворилос€ на ключову проблему соц≥альноњ пол≥тики. ¬ивчаючи цю проблему, UNICEF (ƒит€чий ‘онд ќќЌ) оц≥нював б≥дн≥сть ≥ злиденн≥сть населенн€ в≥дношенн€м середньодушового доходу окремих домашн≥х господарств до такого р≥вн€ доходу, €кий би забезпечив задоволенн€ основних потреб. ћежа б≥дност≥ визначалас€ на р≥вн≥ 35% середньоњ зароб≥тноњ плати 1989 року, а межа злиденност≥ Ч на р≥вн≥ 60% меж≥ б≥дност≥.
ƒан≥ табл. 3.2 характеризують процес зубож≥нн€ населенн€ Ѕолгар≥њ на початку 90-х рок≥в.
“аблиц€ 3.2
ƒ»Ќјћ≤ ј «”Ѕќ∆≤ЌЌя Ќј—≈Ћ≈ЌЌя ЅќЋ√ј–≤ѓ, %, по роках
| —туп≥нь зубож≥нн€ | ||
| Ѕ≥дн≥сть | 13,8 | 62,3 |
| «лиденн≥сть | 2,0 | 32,7 |
якщо 1990 року за межею б≥дност≥ перебувало 13,8%, то 1994 року Ч 62,3%, а у злиденних умовах Ч 32,7%.
як бачимо, структурн≥ й типолог≥чн≥ групуванн€ описов≥; вони характеризують структуру сукупност≥, виокремлюють характерн≥ риси та особливост≥, але р≥зн€тьс€ за р≥внем €к≥сних в≥дм≥нностей м≥ж групами.
—користавшись групуванн€м, можна також ви€вити на€вн≥сть та напр€м звТ€зку м≥ж ознаками, з €ких одна розгл€даЇтьс€ €к результат, ≥нша Ч €к фактор, що впливаЇ на результат. ¬исновок про на€вн≥сть звТ€зку можна зробити на п≥дстав≥ комб≥нац≥йного под≥лу за цими ознаками зг≥дно з характером розм≥щенн€ частот. “ак, за даними табл. 3.3 нам≥р зм≥нити профес≥ю найближчим часом мають переважно незадоволен≥ умовами прац≥ (15 ≥з 22), ≥, навпаки, серед задоволених б≥льш≥сть (26 ≥з 35) зовс≥м не плануЇ зм≥нювати св≥й профес≥йний статус.
“аблиц€ 3.3
ќћЅ≤Ќј÷≤…Ќ»… ѕќƒ≤Ћ –ќЅ≤“Ќ» ≤¬
| —туп≥нь задоволеност≥ умовами прац≥ | „и маЇте нам≥р зм≥нити профес≥ю? | |||
| “ак, найближчим часом | “ак, у перспектив≥ | Ќ≥ | –азом | |
| «адоволений | Ч | |||
| Ќе визначивс€ | ||||
| Ќезадоволений | Ч | |||
| –азом |
якщо результативна ознака к≥льк≥сна, дл€ кожноњ групи за факторною ознакою можна визначити середнЇ значенн€ результативноњ ознаки. «а на€вност≥ звТ€зку м≥ж ознаками групов≥ середн≥ результативноњ ознаки систематично зм≥нюютьс€ в≥д групи до групи (зб≥льшуютьс€ чи зменшуютьс€). “аке групуванн€ нази-
ваЇтьс€ анал≥тичним. ќчевидно, анал≥тичне групуванн€ докладн≥ше й виразн≥ше, н≥ж комб≥нац≥йний под≥л, описуЇ звТ€зок м≥ж ознаками. ѕриклад анал≥тичного групуванн€ наведено в табл. 3.4. ќснова групуванн€ Ч терм≥н збиранн€ врожаю озимоњ пшениц≥ п≥сл€ настанн€ повноњ стиглост≥ зерна (факторна ознака). ожна група характеризуЇтьс€ розм≥ром пос≥вноњ площ≥, з €коњ з≥брано врожай, та середньою врожайн≥стю (результативна ознака). “аблиц€ показуЇ: чим б≥льший терм≥н збиранн€ врожаю, тим менша врожайн≥сть ≥ б≥льш≥ втрати зерна. –≥зниц€ врожайност≥ м≥ж першою ≥ третьою групами становить 20 ц/га.
|
|
|
“аблиц€ 3.4
«јЋ≈∆Ќ≤—“№ ”–ќ∆ј…Ќќ—“≤ ќ«»ћќѓ ѕЎ≈Ќ»÷≤
¬≤ƒ “≈–ћ≤Ќ” «Ѕ»–јЌЌя
| “ерм≥н збиранн€ | «биральна пос≥вна площа, га | ”рожайн≥сть, ц/га |
| —воЇчасно | ||
| « незначним зап≥зненн€м | ||
| «≥ значним зап≥зненн€м | ||
| ” ц≥лому по сукупност≥ |
«ауважимо, що под≥л групувань на три види певною м≥рою в≥дносний. јдже часто групуванн€ ун≥версальн≥: одночасно вид≥л€ютьс€ типи, визначаЇтьс€ склад сукупност≥ й ви€вл€Їтьс€ взаЇмозвТ€зок м≥ж ознаками.
якщо групувальна ознака неперервна, постаЇ питанн€ про к≥льк≥сть груп та меж≥ кожноњ з них. ≥льк≥сть груп залежить в≥д ступен€ вар≥ац≥њ групувальноњ ознаки та обс€гу сукупност≥. “ак, дл€ дискретноњ ознаки, д≥апазон вар≥ац≥њ €коњ обмежений (к≥льк≥сть д≥тей у с≥мТњ, тарифний розр€д тощо), груп, €к правило, ст≥льки, ск≥льки вар≥ант ознаки. ” раз≥ значноњ вар≥ац≥њ дискретноњ ознаки (к≥льк≥сть працюючих на п≥дприЇмств≥, к≥льк≥сть укладених на б≥рж≥ угод), €к ≥ неперервноњ (стаж роботи прац≥вника, соб≥варт≥сть продукц≥њ), д≥апазон вар≥ац≥њ розбиваЇтьс€ на m ≥нтервал≥в.
ќр≥Їнтовно оптимальна к≥льк≥сть груп визначаЇтьс€ за стандартними процедурами, зокрема за формулою —терджеса:
m = 1 + 2,30259 lg n,
де n Ч обс€г сукупност≥; m Ч число ≥нтервал≥в.
≤нтервали €вл€ють собою каркас групувань. Ќа практиц≥ њх утворюють за трьома формальними принципами: р≥вност≥ ≥нтервал≥в; кратност≥ ≥нтервал≥в; р≥вност≥ частот.
” структурних ≥ анал≥тичних групуванн€х найчаст≥ше застосовують принцип р≥вност≥ ≥нтервал≥в. Ўирина кожного ≥нтервалу залежить в≥д д≥апазону вар≥ац≥њ ознаки х та обірунтованого числа груп (≥нтервал≥в) m:
 .
.
¬изначаючи меж≥ ≥нтервал≥в, ширину h доц≥льно округлювати, сам≥ меж≥ сл≥д позначати з такою точн≥стю, щоб под≥л елемент≥в сукупност≥ на групи був однозначним.
якщо д≥апазон вар≥ац≥њ ознаки надто широкий ≥ под≥л значень нер≥вном≥рний, беруть нер≥вн≥ ≥нтервали, зокрема сформован≥ за принципом кратност≥, коли ширина кожного наступного ≥нтервалу в k раз б≥льша (менша), н≥ж попереднього.
ѕрипустимо, що прибутков≥сть актив≥в комерц≥йних банк≥в коливаЇтьс€ в≥д 1 до 42%, а прибутков≥сть кап≥талу Ч в≥д 11 до 165%. «а кожною ознакою утворимо чотири групи (m = 4), скориставшись за прибутков≥стю актив≥в принципом р≥вних ≥нтервал≥в, тобто h = (42 Ц 1): 4ї 10, а за прибутков≥стю кап≥талу Ч принципом кратност≥ ≥нтервал≥в (k = 2). ¬ар≥анти розбитт€ на групи ≥люструЇ табл. 3.5.
“аблиц€ 3.5
¬ј–≤јЌ“» ‘ќ–ћ”¬јЌЌя ≤Ќ“≈–¬јЋ≤¬ √–”ѕ”¬јЌ№ «ј –≤¬Ќ≈ћ ѕ–»Ѕ”“ ќ¬ќ—“≤, %
|
ѕерший та останн≥й ≥нтервали (або один ≥з них) в≥дкрит≥, тобто мають лише одну межу (верхню чи нижню). «а допомогою в≥дкритих ≥нтервал≥в ус≥ крайн≥ значенн€ ознаки, що вар≥юЇ, звод€тьс€ в одну групу, завд€ки чому групуванн€ стаЇ компактним. ћеж≥ ≥нтервал≥в визначаютьс€ по-р≥зному. ” першому вар≥ант≥ групуванн€ верхн€ межа j- го ≥нтервалу зб≥гаЇтьс€ з нижньою межею (j + 1)-го ≥нтервалу. ѕравило в≥днесенн€ межових значень ознаки до в≥дпов≥дного ≥нтервалу задають слова, що стосуютьс€ в≥дкритих ≥нтервал≥в. «окрема, слово Ђдої в першому ≥нтервал≥ означаЇ, що нижню межу сл≥д уважати належною, а верхню Ч не належною ≥нтервалу.
” другому вар≥ант≥ групуванн€ верхн€ межа j- го ≥нтервалу ≥ нижн€ межа (j + 1)-го ≥нтервалу р≥зн€тьс€ м≥ж собою. ” цьому раз≥ обидв≥ меж≥ вважаютьс€ такими, що належать ≥нтервалу.
≤нтервали типолог≥чного групуванн€ формуютьс€ не за математичними принципами, а за соц≥ально-економ≥чним зм≥стом. ћежа ≥нтервалу розгл€даЇтьс€ €к умовна межа переходу к≥лькост≥ в нову €к≥сть. „исло груп залежить в≥д к≥лькост≥ ≥снуючих тип≥в. Ќаприклад, групуючи чолов≥к≥в за ознакою працездатност≥, застосовують в≥ков≥ групи, рок≥в:
0Ч15 Ч особи допрацездатного в≥ку;
16Ч59 Ч працездатного;
60 ≥ б≥льше Ч старш≥ за працездатний в≥к.
ѕринцип р≥вних частот використовують нечасто ≥ переважно в анал≥тичних групуванн€х, щоб уникнути зважуванн€ групових середн≥х (дисперс≥йний анал≥з результат≥в експерименту).
√рупуванн€ за одн≥Їю ознакою називаЇтьс€ простим, за двома ≥ б≥льше ознаками Ч комб≥нац≥йним. ” комб≥нац≥йних групуванн€х ознаки ≥Їрарх≥чно впор€дковуютьс€ за зм≥стом чи за вагом≥стю.
√рупи, утворен≥ за першою ознакою, под≥л€ютьс€ на п≥дгрупи за другою, а т≥, у свою чергу, можуть под≥л€тис€ на п≥дгрупи за третьою ознакою ≥ т. д. Ќа кожному етап≥ под≥лу використовуЇтьс€ лише одна ознака, тобто в≥дбуваЇтьс€ посл≥довне описуванн€ груп. ≥льк≥сть п≥дгруп дор≥внюЇ добутку числа групувальних ознак на число градац≥й за кожною з них. ” раз≥ трьох ≥ б≥льше групувальних ознак сукупн≥сть стр≥мко подр≥бнюЇтьс€, групи ви€вл€ютьс€ нечисленними, а характеристики груп Ч ненад≥йними.
јльтернативою комб≥нац≥йному групуванню Ї багатовим≥рне, коли групи утворюютьс€ за певною множиною ознак одночасно. ћ≥рою под≥бност≥ елемент≥в Ї р≥зн≥ критер≥њ ≥, €к насл≥док, Ч р≥зн≥ методи багатовим≥рного групуванн€. Ќайпрост≥шим серед них Ї групуванн€ за ≥нтегральним показником, наприклад за рейтинговою оц≥нкою. ” такому раз≥ багатовим≥рне групуванн€ зводитьс€ до простого.
≤нод≥ доводитьс€ перегруповувати дан≥, передус≥м щоб забезпечити пор≥вн€нн≥сть структур двох сукупностей за одн≥Їю ≥ т≥Їю самою ознакою. –езультат перегрупуванн€ називають вторинним групуванн€м. ѕерегрупуванн€ виконують або обТЇднанн€м, або розбитт€м ≥нтервал≥в первинного групуванн€.
якщо меж≥ ≥нтервал≥в первинного ≥ вторинного групувань зб≥гаютьс€, частоти (частки) обТЇднувальних ≥нтервал≥в просто п≥дсумовуютьс€. оли виконуЇтьс€ розбитт€ ≥нтервалу первинного групуванн€, частоти под≥л€ютьс€ м≥ж новоутвореними групами пропорц≥йно до сп≥вв≥дношенн€ частин довжини початкового ≥нтервалу. ѕрипускаЇтьс€, що всередин≥ ≥нтервалу под≥л р≥вном≥рний.
“ехн≥ку перегрупуванн€ даних розгл€немо на приклад≥ под≥лу працюючих за розм≥ром середньом≥с€чноњ зароб≥тноњ плати у двох галуз€х промисловост≥ (табл. 3.6).
“аблиц€ 3.6
ѕќƒ≤Ћ ѕ–ј÷ёё„»’ «ј –≤¬Ќ≈ћ
—≈–≈ƒЌ№ќћ≤—я„Ќќѓ «ј–ќЅ≤“Ќќѓ ѕЋј“»
| √алузь ј | √алузь ¬ | ||
| «ароб≥тна плата, грн. | „астка працюючих, % | «ароб≥тна плата, грн. | „астка працюючих, % |
| ƒо 160 | ƒо 160 | ||
| 160 Ч 180 | 160 Ч 190 | ||
| 180 Ч 200 | 190 Ч 220 | ||
| 200 Ч 220 | 220 Ч 250 | ||
| 220 Ч 240 | 250 Ч 280 | ||
| 240 ≥ б≥льше | 280 ≥ б≥льше | ||
| –азом | –азом |
–езультати первинного групуванн€ безпосередньо пор≥вн€ти не можна, оск≥льки ≥нтервали групуванн€ р≥зн≥: у галуз≥ ј ширина ≥нтервалу 20, у галуз≥ ¬ Ч 30 грн. ѕерегрупуЇмо дан≥, утворивши пТ€ть груп з ≥нтервалом h = 40 грн. ќчевидно, ≥нтервали под≥лу в галуз≥ ј потр≥бно обТЇднати, а в галуз≥ ¬ Ч розбити. –езультати вторинного групуванн€ ≥люструЇ табл. 3.7.
“аблиц€ 3.7
¬“ќ–»ЌЌ≈ √–”ѕ”¬јЌЌя ѕ–ј÷ёё„»’
«ј –≤¬Ќ≈ћ —≈–≈ƒЌ№ќћ≤—я„Ќќѓ «ј–ќЅ≤“Ќќѓ ѕЋј“»
| «ароб≥тна плата, грн. | „астка працюючих, % | |
| √алузь ј | √алузь ¬ | |
| ƒо 160 | ||
| 160 Ч 200 | 20 + 26 = 46 | 
|
| 200 Ч 240 | 23 + 9 = 32 | 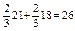
|
| 240 Ч 280 | 
| |
| 280 ≥ б≥льше | Ч | |
| –азом |
ѕор≥вн€вши частки вторинного групуванн€, побачимо, що в галуз≥ ¬ сукупн≥сть працюючих за р≥внем зароб≥тноњ плати б≥льш диференц≥йована. ѕерегрупуванн€м даних можна перейти в≥д структурного групуванн€ до типолог≥чного.
–€ди розпод≥лу
ѕ≥сл€ обробки к≥льк≥сних значень, њх систематизац≥њ, ми д≥стаЇмо певний цифровий р€д, €кий називаЇтьс€ статистичний р€д. ¬≥н маЇ дв≥ форми: р€д розпод≥лу ≥ динам≥чний р€д.
І –€д розпод≥лу Ц це впор€дкований розпод≥л сукупност≥ на групи за певною вар≥юючою ознакою, розташованою в певному пор€дку (зростанн€, спаданн€ тощо).
¬ид≥л€ють атрибутивн≥ ≥ вар≥ац≥йн≥ р€ди розпод≥лу.
–€д розпод≥лу одиниць сукупност≥, в основу €кого покладено €к≥сн≥ ознаки називаЇтьс€ атрибутивним. ѕрикладом атрибутивного р€ду розпод≥лу може бути розпод≥л населенн€ на м≥ське ≥ с≥льське.
–€д розпод≥лу одиниць сукупност≥ за ознакою, що маЇ к≥льк≥сне вираженн€, називаЇтьс€ вар≥ац≥йним.
¬ар≥ац≥йний р€д розпод≥лу маЇ своњ особливост≥. ¬≥н складаЇтьс€ з двох елемент≥в: вар≥ант≥в ≥ частот.
І ¬ар≥антами називають числов≥ значенн€ розм≥р≥в к≥льк≥сноњ ознаки. „исла, €к≥ в≥дпов≥дають цим вар≥антам, називаютьс€ частотами. „астоти можуть виражатис€ €к в абсолютних, так ≥ у в≥дносних одиниц€х (напр. в≥дсотках).
¬≥дпов≥дно до вар≥ац≥њ ознаки, вар≥ац≥йн≥ р€ди розпод≥лу можуть бути дискретними ≥ ≥нтервальними. ¬ дискретному р€д≥ розпод≥лу к≥льк≥сна ознака приймаЇ т≥льки ц≥л≥ значенн€. оли значенн€ вар≥ант≥в р€ду виражено у вигл€д≥ ≥нтервалу, такий р€д розпод≥лу називаЇтьс€ ≥нтервальним.
| √рупи с≥мей - вар≥ант | ≥льк≥сть с≥мей - частота | јкумул€тивна частка |
І Ќакопиченн€ часток по м≥р≥ зростанн€ (спаданн€) ознаки називаЇтьс€ акумул€тивна частка.
«а характером розпод≥лу вар≥ац≥йн≥ р€ди можуть бути симетричн≥ ≥ асиметричн≥.
–€д розпод≥лу, де частоти спочатку наростають, а пот≥м спадають, називаЇтьс€ симетричним. –€д розпод≥лу, в €кому частоти розташован≥ несиметрично в≥д середини, називаЇтьс€ асиметричним або скошеним.
√раф≥чно р€ди розпод≥лу зображаютьс€ у вигл€д≥ г≥стограми або пол≥гону (де ось OY Ц результативна ознака, ось OX Ц факторна ознака):

ƒо характеристик вар≥ац≥њ в≥днос€тьс€ наступн≥ показники: розмах вар≥ац≥њ, середнЇ л≥н≥йне в≥дхиленн€, середн≥й квадрат в≥дхиленн€, середнЇ квадратичне в≥дхиленн€, коеф≥ц≥Їнти вар≥ац≥њ.
«адача є1. Ќехай маЇмо дв≥ бригади ≥з такою продуктивн≥стю прац≥ прац≥вник≥в:
1) 29, 31, 33, 30, 34;
2) 31, 32, 37, 27, 30.
Ќеобх≥дно пор≥вн€ти ц≥ дв≥ бригади.
—початку знайдемо середню продуктивну працю по кожн≥й бригад≥:


–озмах вар≥ац≥њ становить р≥зницю м≥ж м≥н≥мальним ≥ максимальним значенн€м ознаки: R = xmax Ц xmin.
¬ нашому випадку:
R1 = 34 Ц 29 = 5
R2 = 37 Ц 27 = 10
«аконом≥рн≥сть розпод≥лу
—татистична сукупн≥сть формуЇтьс€ п≥д впливом причин та умов, з одного боку Ч типових, сп≥льних дл€ вс≥х елемент≥в сукупност≥, а з ≥ншого Ч випадкових, ≥ндив≥дуальних. ÷≥ чинники взаЇмозвТ€зан≥, а њх сп≥льна взаЇмод≥€ визначаЇ €к ≥ндив≥дуальн≥ значенн€ ознак, так ≥ розпод≥л останн≥х у межах сукупност≥. ’арактерн≥ властивост≥ структури статистичноњ сукупност≥ в≥дбиваютьс€ в р€дах розпод≥лу.
–€д розпод≥лу складаЇтьс€ з двох елемент≥в: вар≥ант Ч
значень групувальноњ ознаки xj та частот (часток) fj. —аме у сп≥вв≥дношенн≥ вар≥ант ≥ частот ви€вл€Їтьс€ законом≥рн≥сть розпод≥лу.
«алежно в≥д статистичноњ природи вар≥ант р€ди розпод≥лу под≥л€ютьс€ на атрибутивн≥ та вар≥ац≥йн≥. „астотними характеристиками будь-€кого р€ду Ї абсолютна чисельн≥сть j -њ групи Ч частота fj та в≥дносна частота j -њ групи Ч частка dj. ќчевидно, що  , а
, а  , або 100%. ƒодатковою характеристикою вар≥ац≥йних р€д≥в Ї кумул€тивна частота (частка), що €вл€Ї собою результат посл≥довного обТЇднанн€ груп ≥ п≥дсумовуванн€ в≥дпов≥дних њм частот (часток). умул€тивна частота
, або 100%. ƒодатковою характеристикою вар≥ац≥йних р€д≥в Ї кумул€тивна частота (частка), що €вл€Ї собою результат посл≥довного обТЇднанн€ груп ≥ п≥дсумовуванн€ в≥дпов≥дних њм частот (часток). умул€тивна частота  (частка
(частка  ) характеризуЇ обс€г сукупност≥ з≥ значенн€ми вар≥ант, €к≥ не перевищують xj (табл. 5.1).
) характеризуЇ обс€г сукупност≥ з≥ значенн€ми вар≥ант, €к≥ не перевищують xj (табл. 5.1).
¬ар≥ац≥йний р€д може бути дискретним або ≥нтервальним. якщо вар≥ац≥йний р€д ≥нтервальний з нер≥вними ≥нтервалами, то його частотн≥ характеристики непор≥вн€нн≥. “од≥, анал≥зуючи розпод≥л, використовують щ≥льн≥сть частоти (частки) на одиницю ≥нтервалу, тобто  або
або  .
.
“аблиц€ 5.1
„ј—“ќ“Ќ≤ ’ј–ј “≈–»—“» » –яƒ≤¬ –ќ«ѕќƒ≤Ћ”
| «наченн€ вар≥ант хj | „астоти fj | „астки dj | умул€тивн≥ | |
частоти 
| частки 
| |||
| х 1 | f 1 | d 1 | f 1 | d 1 |
| х 2 | f 2 | d 2 | f 1 + f 2 | d 1 + d 2 |
| х 3 | f 3 | d 3 | f 1 + f 2 + f 3 | d 1 + d 2 + d 3 |
| ... | ... | ... | ... | ... |
| хm | fm | dm | 
| |
| –азом | 
| ´ | ´ |
як приклад розгл€немо розпод≥л ф≥рм рег≥ону за р≥внем фондоозброЇност≥ прац≥ в розрахунку на одного працюючого (табл. 5.2). «г≥дно з≥ значенн€ми кумул€тивних часток на б≥льшост≥ ф≥рм (50,6%) фондоозброЇн≥сть прац≥ не перевищуЇ 5 млн грн. ў≥льн≥сть розпод≥лу з≥ зростанн€м ширини ≥нтервалу зменшуЇтьс€.
“аблиц€ 5.2
–ќ«ѕќƒ≤Ћ ‘≤–ћ –≈√≤ќЌ” «ј –≤¬Ќ≈ћ ‘ќЌƒќќ«Ѕ–ќ™Ќќ—“≤ ѕ–ј÷≤
| ‘ондоозброЇн≥сть прац≥, млн грн. | „астка dj, % | умул€тивна частка 
| ў≥льн≥сть частки gj, % |
| 1 Ч 2 | 13,4 | 13,4 | 13,4 |
| 2 Ч 5 | 37,2 | 50,6 | 12,4 |
| 5 Ч 10 | 23,5 | 74,1 | 4,7 |
| 10 Ч 20 | 16,8 | 90,9 | 4,7 |
| 20 Ч 50 | 9,1 | 100,0 | 0,3 |
| –азом | ´ | ´ |
ожний розпод≥л маЇ характерн≥ особливост≥. Ќайтипов≥ш≥ з них подано в р€дах розпод≥лу (табл. 5.3). √рупувальною ознакою Ї тарифний розр€д, значенн€ €кого вар≥юють у межах в≥д 2 до 6. ѕрипустимо, що розпод≥ли роб≥тник≥в умовних профес≥й за р≥внем квал≥ф≥кац≥њ р≥зн≥. “ак, у р€дах ј ≥ ¬ розпод≥л частот однаковий, але центри розпод≥лу, навколо €ких групуютьс€ ≥ндив≥дуальн≥ значенн€, р≥зн≥: в р€ду ј Ч 5-й розр€д, в р€ду ¬ Ч 4-й. ” р€дах —, D, центр розпод≥лу такий самий, €к ≥ в р€ду ¬, Ч 4-й, проте форма розпод≥лу р≥зна. –€ди ¬ ≥ — р≥зн€тьс€ межами вар≥ац≥њ; у р€дах — ≥ D при однакових межах вар≥ац≥њ ≥ симетричному розпод≥л≥ частот р≥зний ступ≥нь вит€гнутост≥ вздовж ос≥ ординат, р≥зна крутизна розпод≥лу: у розпод≥л≥ — лише 36% обс€гу сукупност≥ групуЇтьс€ навколо центра, у розпод≥л≥ D Ч 76% обс€гу. –озпод≥л в≥др≥зн€Їтьс€ в≥д ≥нших асиметричн≥стю в≥дносно центра.
“аблиц€ 5.3
–ќ«ѕќƒ≤Ћ –ќЅ≤“Ќ» ≤¬ «ј –≤¬Ќ≈ћ ¬јЋ≤‘≤ ј÷≤ѓ
| “арифний розр€д | ѕрофес≥њ | ||||
| ј | ¬ | — | D | ||
| Ч | Ч | ||||
| Ч | |||||
| Ч | |||||
| –азом |
ќтже, поглиблений анал≥з законом≥рностей розпод≥лу передбачаЇ характеристику зазначених особливостей сукупност≥, зокрема:
а) визначенн€ типового р≥вн€ ознаки, €кий Ї центром т€ж≥нн€;
б) вим≥рюванн€ вар≥ац≥њ ознаки, ступен€ згрупованост≥ ≥ндив≥дуальних значень ознаки навколо центра розпод≥лу;
в) оц≥нюванн€ особливостей вар≥ац≥њ, ступен€ њњ в≥дхиленн€ в≥д симетр≥њ;
г) оц≥нюванн€ нер≥вном≥рност≥ розпод≥лу значень ознаки м≥ж окремими елементами сукупност≥, тобто ступ≥нь њх концентрац≥њ.
Ѕазою анал≥зу законом≥рностей розпод≥лу Ї вар≥ац≥йний р€д Ч дискретний або ≥нтервальний Ч з р≥вними ≥нтервалами.
’арактеристики центру розпод≥лу
÷ентром т€ж≥нн€ будь-€коњ статистичноњ сукупност≥ Ї типовий р≥вень ознаки, узагальнююча характеристика всього розмањтт€ њњ ≥ндив≥дуальних значень. “акою характеристикою Ї середн€ величина  . «а даними р€ду розпод≥лу середн€ обчислюЇтьс€ €к ариф≠метична зважена; вагами Ї частоти fj або частки dj:
. «а даними р€ду розпод≥лу середн€ обчислюЇтьс€ €к ариф≠метична зважена; вагами Ї частоти fj або частки dj:
 ,
,  ,
,
де j Ч номер групи; m Ч число груп.
¬ ≥нтервальних р€дах, припускаючи р≥вном≥рний розпод≥л елемент≥в сукупност≥ в межах j -го ≥нтервалу, €к вар≥анту  використовують середину ≥нтервалу. ѕри цьому ширину в≥дкритого ≥нтервалу умовно вважають такою самою, €к сус≥днього закритого ≥нтервалу.
використовують середину ≥нтервалу. ѕри цьому ширину в≥дкритого ≥нтервалу умовно вважають такою самою, €к сус≥днього закритого ≥нтервалу.
ƒан≥ дл€ розрахунку середнього р≥вн€ в ≥нтервальному р€ду розпод≥лу наведено в табл. 5.4. «г≥дно з розрахунками, у середньо-
му на одного члена домогосподарства припадаЇ = 1800: 200 =
= 9 м2 житловоњ площ≥. ÷е типовий р≥вень забезпеченост≥ населенн€ житлом.
“аблиц€ 5.4
–ќ«ѕќƒ≤Ћ ƒќћќ√ќ—ѕќƒј–—“¬ ћ≤—“ј «ј –≤¬Ќ≈ћ
«јЅ≈«ѕ≈„≈Ќќ—“≤ ∆»“Ћќћ
| ∆итлова площа на одного члена домогосподарства, м2 | ≥льк≥сть домо- господарств fj | xj | xj fj | умул€тивна частка 
|
| ƒо 5 | ||||
| 5 Ч 7 | ||||
| 7 Ч 9 | ||||
| 9 Ч 11 | ||||
| 11 Ч 13 | ||||
| 13 Ч 15 | ||||
| 15 ≥ б≥льше | ||||
| –азом | ´ | ´ |
ќкр≥м типового р≥вн€ важливе значенн€ маЇ дом≥нанта, тобто найб≥льш поширене значенн€ ознаки. “аке значенн€ називають модою (ћо). ” дискретному р€ду моду визначають безпосередньо за найб≥льшою частотою (часткою). Ќаприклад, €кщо депозитна ставка у восьми комерц≥йних банк≥в Ч 12% р≥чних, а в двох Ч 10%, то модальною Ї ставка 12%.
¬ ≥нтервальному р€ду за тим самим принципом визначаЇтьс€ модальний ≥нтервал, а в раз≥ потреби конкретне модальне значенн€ в середин≥ ≥нтервалу обчислюЇтьс€ за ≥нтерпол€ц≥йною формулою
 ,
,
де  та h Ч в≥дпов≥дно нижн€ межа та ширина модального ≥нтервалу,
та h Ч в≥дпов≥дно нижн€ межа та ширина модального ≥нтервалу,  ,
,  ,
,  Ч частоти (частки) в≥дпов≥дно модального, передмодального та п≥сл€модального ≥нтервал≥в.
Ч частоти (частки) в≥дпов≥дно модального, передмодального та п≥сл€модального ≥нтервал≥в.
«а даними табл. 5.4 модальним Ї ≥нтервал 7 Ч 9, що маЇ найб≥льшу частоту  ; ширина модального ≥нтервалу h = 2; нижн€ межа х 0 = 7; передмодальна частота = 39, п≥сл€модальна Ч = 42. «а такого сп≥вв≥дношенн€ частот модальне значенн€ забезпеченост≥ населенн€ житлом:
; ширина модального ≥нтервалу h = 2; нижн€ межа х 0 = 7; передмодальна частота = 39, п≥сл€модальна Ч = 42. «а такого сп≥вв≥дношенн€ частот модальне значенн€ забезпеченост≥ населенн€ житлом:
 = 8,1 м2.
= 8,1 м2.
ƒл€ моди €к дом≥нанти число в≥дхилень (х Ц ћо) м≥н≥мальне. ќск≥льки мода не залежить в≥д крайн≥х значень ознаки, то њњ до-
ц≥льно використовувати тод≥, коли р€д розпод≥лу маЇ невизначен≥ меж≥.
’арактеристикою центра розпод≥лу вважаЇтьс€ також мед≥ана (ће) Ч значенн€ ознаки, €ке припадаЇ на середину впор€дкованого р€ду, под≥л€Ї його навп≥л Ч на дв≥ р≥вн≥ за обс€гом частини. ¬изначаючи мед≥ану, використовують кумул€тивн≥ частоти  або частки
або частки  . ” дискретному р€ду мед≥аною буде значенн€ ознаки, кумул€тивна частота €кого перевищуЇ половину обс€гу сукупност≥, тобто
. ” дискретному р€ду мед≥аною буде значенн€ ознаки, кумул€тивна частота €кого перевищуЇ половину обс€гу сукупност≥, тобто  (дл€ кумул€тивноњ частки
(дл€ кумул€тивноњ частки  ).
).
¬ ≥нтервальному р€ду за цим принципом визначають мед≥анний ≥нтервал, а значенн€ мед≥ани в середин≥ ≥нтервалу, €к ≥ значенн€ моди, обчислюють за ≥нтерпол€ц≥йною формулою:
 ,
,
де x 0 та h Ч в≥дпов≥дно нижн€ межа та ширина мед≥анного ≥нтервалу; f me Ч частота мед≥анного ≥нтервалу;  Ч кумул€тивна частота передмед≥анного ≥нтервалу.
Ч кумул€тивна частота передмед≥анного ≥нтервалу.
«а даними табл. 5.4 половина обс€гу сукупност≥  припадаЇ на ≥нтервал 7 Ч 9 з частотою
припадаЇ на ≥нтервал 7 Ч 9 з частотою  = 51; передмед≥анна кумул€тивна частота = 56. ќтже, мед≥ана забезпеченост≥ населенн€ житлом:
= 51; передмед≥анна кумул€тивна частота = 56. ќтже, мед≥ана забезпеченост≥ населенн€ житлом:
 м2.
м2.
” симетричному розпод≥л≥ вс≥ три зазначен≥ характеристики центра розпод≥лу однаков≥:  , у пом≥рно асиметричному в≥дстань мед≥ани до середньоњ втрич≥ менша за в≥дстань середньоњ до моди, тобто
, у пом≥рно асиметричному в≥дстань мед≥ани до середньоњ втрич≥ менша за в≥дстань середньоњ до моди, тобто  . —аме таке сп≥вв≥дношенн€ характеристик центра розпод≥лу в розгл€нутому приклад≥:
. —аме таке сп≥вв≥дношенн€ характеристик центра розпод≥лу в розгл€нутому приклад≥:
3 (9 Ц 8,7) = 9 Ц 8,1.
ћед≥ана, €к ≥ мода, не залежить в≥д крайн≥х значень ознаки; сума модул≥в в≥дхилень вар≥ант в≥д мед≥ани м≥н≥мальна, тобто вона маЇ властив≥сть л≥н≥йного м≥н≥муму:
 .
.
÷ю властив≥сть мед≥ани можна використати при проектуванн≥ розм≥щенн€ зупинок м≥ського транспорту, загот≥вельних пункт≥в тощо.
ќкр≥м моди ≥ мед≥ани, в анал≥з≥ законом≥рностей розпод≥лу використовуютьс€ також квартил≥ та децил≥. вартил≥ Ч це вар≥анти, €к≥ под≥л€ють обс€ги сукупност≥ на чотири р≥вн≥ частини, децил≥ Ч на дес€ть р≥вних частин. ÷≥ характеристики визначаютьс€ на основ≥ кумул€тивних частот (часток) за аналог≥Їю з мед≥аною, €ка Ї другим квартилем або пТ€тим децилем.
” р€ду розпод≥лу (див. табл. 5.4) перший квартиль становить 6,7 м2, перший дециль Ч 5,2 м2, девТ€тий Ч 13,3 м2:
 ;
;
 ;
;
 .
.
ќтже, у 25% с≥мей забезпечен≥сть житлом не перевищуЇ 6,7 м2, серед 10% малозабезпечених найвищий р≥вень становить 5,2 м2, а серед 10% найб≥льш забезпечених нижн€ межа Ч 13,3 м2.
’арактеристики вар≥ац≥њ
¬ одних сукупност€х ≥ндив≥дуальн≥ значенн€ ознаки щ≥льно групуютьс€ навколо центра розпод≥лу, в ≥нших Ч значно в≥дхил€ютьс€. „им менш≥ в≥дхиленн€, тим однор≥дн≥ша сукупн≥сть, а отже, тим б≥льш над≥йн≥ й типов≥ характеристики центра розпод≥лу, передус≥м середн€ величина. ¬им≥рюванн€ ступен€ коливанн€ ознаки, њњ вар≥ац≥њ Ч нев≥дТЇмна складова анал≥зу законом≥рностей розпод≥лу. ћ≥ри вар≥ац≥њ широко використовуютьс€ у практичн≥й д≥€льност≥: дл€ оц≥нюванн€ диференц≥ац≥њ домашн≥х господарств за р≥внем доходу, ф≥нансового ризику ≥нвестуванн€, ритм≥чност≥ роботи п≥дприЇмств, сталост≥ врожайност≥ с≥льськогосподарських культур тощо.
Ќа основ≥ характеристик вар≥ац≥њ оц≥нюЇтьс€ ≥нтенсивн≥сть структурних зрушень, щ≥льн≥сть взаЇмозвТ€зк≥в соц≥ально-еконо≠м≥чних €вищ, точн≥сть результат≥в виб≥ркового обстеженн€.
ƒл€ вим≥рюванн€ та оц≥нюванн€ вар≥ац≥њ використовуютьс€ абсолютн≥ та в≥дносн≥ характеристики. ƒо абсолютних належать: вар≥ац≥йний розмах, середнЇ л≥н≥йне та середнЇ квадратичне в≥дхиленн€, дисперс≥њ; в≥дносн≥ характеристики подаютьс€ низкою коеф≥ц≥Їнт≥в вар≥ац≥њ, локал≥зац≥њ, концентрац≥њ.
¬ар≥ац≥йний розмах R Ч це р≥зниц€ м≥ж максимальним ≥ м≥н≥мальним значенн€ми ознаки: R = x max Ц x min. ¬≥н характеризуЇ д≥апазон вар≥ац≥њ, наприклад родючост≥ ірунт≥в у рег≥он≥, продуктив≠ност≥ прац≥ в галуз€х промисловост≥ тощо. Ѕезперечною перевагою вар≥ац≥йного розмаху €к м≥ри вар≥ац≥њ Ї простота його обчисленн€ й тлумаченн€.
ѕроте, коли частоти крайн≥х вар≥ант надто мал≥, вар≥ац≥йний розмах неадекватно характеризуЇ вар≥ац≥ю. ” таких випадках використовують квартильн≥ або децильн≥ розмахи. вартильний розмах  охоплюЇ 50% обс€гу сукупност≥, децильний
охоплюЇ 50% обс€гу сукупност≥, децильний  Ч 60% або
Ч 60% або  Ч 80%.
Ч 80%.
≤нш≥ абсолютн≥ характеристики вар≥ац≥њ враховують ус≥ в≥дхиленн€ значень ознаки в≥д центра розпод≥лу, поданого середньою величиною. ќск≥льки алгебрањчна сума в≥дхилень  , то використовуютьс€ або модул≥ в≥дхилень
, то використовуютьс€ або модул≥ в≥дхилень  , або квадрати в≥дхилень
, або квадрати в≥дхилень  . ”загальнюючою характеристикою вар≥ац≥њ Ї середнЇ в≥дхиленн€:
. ”загальнюючою характеристикою вар≥ац≥њ Ї середнЇ в≥дхиленн€:
а) л≥н≥йне
 ;
;
б) квадратичне, або стандартне
 ;
;
в) дисперс≥€ (середн≥й квадрат в≥дхилень)
 .
.
Ќа п≥дстав≥ первинних, незгрупованих даних наведен≥ характеристики обчислюють за принципом незваженоњ середньоњ:
 або
або  .
.
—ереднЇ л≥н≥йне  та середнЇ квадратичне
та середнЇ квадратичне  в≥дхиленн€ Ї безпосередн≥ми м≥рами вар≥ац≥њ. ÷е ≥менован≥ числа (в одиниц€х вим≥рюванн€ ознаки), за зм≥стом вони ≥дентичн≥, проте завд€ки математичним властивост€м
в≥дхиленн€ Ї безпосередн≥ми м≥рами вар≥ац≥њ. ÷е ≥менован≥ числа (в одиниц€х вим≥рюванн€ ознаки), за зм≥стом вони ≥дентичн≥, проте завд€ки математичним властивост€м  . оли обс€г сукупност≥ досить великий ≥ розпод≥л ознаки, що вар≥юЇ, наближаЇтьс€ до нормального, то
. оли обс€г сукупност≥ досить великий ≥ розпод≥л ознаки, що вар≥юЇ, наближаЇтьс€ до нормального, то  , а
, а  . «наченн€ ознаки в межах
. «наченн€ ознаки в межах 

 мають 68,3% обс€гу сукупност≥, у межах
мають 68,3% обс€гу сукупност≥, у межах  Ч 95,4%, у межах
Ч 95,4%, у межах  Ч 99,7%. ÷е в≥доме Ђправило трьох сигмї. ѕри значн≥й асиметр≥њ розпод≥лу (див. п≥дрозд. 5.4) розрахунок не маЇ сенсу.
Ч 99,7%. ÷е в≥доме Ђправило трьох сигмї. ѕри значн≥й асиметр≥њ розпод≥лу (див. п≥дрозд. 5.4) розрахунок не маЇ сенсу.
Ќа основ≥ взаЇмозвТ€зку м≥ж вар≥ац≥йним розмахом R, середн≥м квадратичним в≥дхиленн€м ≥ чисельн≥стю сукупност≥ n –. ѕ≥рсон обчислив коеф≥ц≥Їнти k, за допомогою €ких ор≥Їнтовно можна визначити середнЇ квадратичне в≥дхиленн€ за вар≥ац≥йним розмахом:  . «наченн€ коеф≥ц≥Їнт≥в k наведено в табл. 5.5.
. «наченн€ коеф≥ц≥Їнт≥в k наведено в табл. 5.5.
“аблиц€ 5.5
ќ≈‘≤÷≤™Ќ“» k ƒЋя –≤«Ќќ√ќ ќЅ—я√” —” ”ѕЌќ—“≤
| n | |||||||
| k | 0,32 | 0,27 | 0,24 | 0,23 | 0,22 | 0,20 | 0,18 |
ќчевидний взаЇмозвТ€зок середнього квадратичного в≥дхиленн€ та дисперс≥њ:  . ƒисперс≥€ входить до б≥льшост≥ теорем теор≥њ ймов≥рностей, €к≥ Ї фундаментом математичноњ статистики, ≥ широко використовуЇтьс€ дл€ вим≥рюванн€ звТ€зку й перев≥рки статистичних г≥потез. ¬иди та властивост≥ дисперс≥й розгл€даютьс€ в п≥дрозд. 5.5.
. ƒисперс≥€ входить до б≥льшост≥ теорем теор≥њ ймов≥рностей, €к≥ Ї фундаментом математичноњ статистики, ≥ широко використовуЇтьс€ дл€ вим≥рюванн€ звТ€зку й перев≥рки статистичних г≥потез. ¬иди та властивост≥ дисперс≥й розгл€даютьс€ в п≥дрозд. 5.5.
ѕри пор≥вн€нн≥ вар≥ац≥њ р≥зних ознак або одн≥Їњ ознаки в р≥зних сукупност€х використовуютьс€ коеф≥ц≥Їнти вар≥ац≥њ V. ¬они визначаютьс€ в≥дношенн€м абсолютних ≥менованих характеристик вар≥ац≥њ (, , R) до центра розпод≥лу, найчаст≥ше виражаютьс€ у процентах. «наченн€ цих коеф≥ц≥Їнт≥в залежить в≥д того, €ка саме абсолютна характеристика вар≥ац≥њ використовуЇтьс€. ќтже, маЇмо коеф≥ц≥Їнти вар≥ац≥њ:
л≥н≥йний  ;
;
квадратичний  ;
;
осцил€ц≥њ  .
.
якщо центр розпод≥лу поданий мед≥аною, то за в≥дносну м≥ру вар≥ац≥њ беруть квартильний коеф≥ц≥Їнт вар≥ац≥њ
 .
.
ƒл€ оц≥нюванн€ ступен€ вар≥ац≥њ застосовують також сп≥вв≥дношенн€ децил≥в. “ак, коеф≥ц≥Їнт децильноњ диференц≥ац≥њ показуЇ кратн≥сть сп≥вв≥дношенн€ девТ€того та першого децил≥в:
 .
.
Ќеобх≥дн≥ дл€ розрахунку узагальнюючих характеристик вар≥ац≥њ величини подано в табл. 5.6 на приклад≥ розпод≥лу домогосподарств за р≥внем забезпеченост≥ житлом. —ередн€ розпод≥лу становить 9 м2.
“аблиц€ 5.6
ƒќ –ќ«–ј’”Ќ ” ”«ј√јЋ№Ќёё„»’ ’ј–ј “≈–»—“» ¬ј–≤ј÷≤ѓ
| xj | fj | 
| 
| 
| 
|
| Ц5 | |||||
| Ц3 | |||||
| Ц1 | |||||
| –азом | ´ | ´ |
«г≥дно з розрахунками:
 2,53 м2;
2,53 м2;
 ;
;
 м2;
м2;
 .
.
ƒецильний коеф≥ц≥Їнт VD = 13,3: 5,2 = 2,5 показуЇ, що нижн€ межа 10% в≥дносно забезпечених житлом домогосподарств в 2,5 раза перевищуЇ верхню межу 10% малозабезпечених домогосподарств.
’арактеристики форми розпод≥лу
јнал≥з законом≥рностей розпод≥лу передбачаЇ оц≥нюванн€ ступен€ однор≥дност≥ сукупност≥, асиметр≥њ та ексцесу розпод≥лу.
ќднор≥дн≥сть сукупност≥ Ч передумова використанн€ ≥нших ста≠тистичних метод≥в (середн≥х величин, регрес≥йного анал≥зу тощо). ќднор≥дними вважаютьс€ так≥ сукупност≥, елементи €ких мають сп≥льн≥ властивост≥ ≥ належать до одного типу, класу. ѕри цьому однор≥дн≥сть означаЇ не повну тотожн≥сть властивостей елемент≥в, а лише на€вн≥сть у них сп≥льного в ≥стотному, головному.
¬ однор≥дних сукупност€х розпод≥ли одновершинн≥ (одномодальн≥). Ѕагатовершинн≥сть св≥дчить про неоднор≥дний склад сукупност≥, про р≥знотипов≥сть окремих складових. ” такому раз≥ необх≥дно перегрупувати дан≥, виокремити однор≥дн≥ групи. ритер≥Їм однор≥дност≥ сукупност≥ вважаЇтьс€ квадратичний коеф≥ц≥Їнт вар≥ац≥њ, €кий завд€ки властивост€м  в симетричному розпод≥л≥ становить
в симетричному розпод≥л≥ становить  . «г≥дно з цим критер≥Їм сукупн≥сть домогосподарств за р≥внем забезпеченост≥ житлом практично однор≥дна (
. «г≥дно з цим критер≥Їм сукупн≥сть домогосподарств за р≥внем забезпеченост≥ житлом практично однор≥дна ( ).
).
«-пом≥ж одновершинних розпод≥л≥в Ї симетричн≥ та асиметричн≥ (скошен≥), гостро- та плосковершинн≥. ” симетричному розпод≥л≥ р≥внов≥ддален≥ в≥д центра значенн€ ознаки мають однаков≥ частоти, в асиметричному Ч вершина розпод≥лу зм≥щена. Ќапр€м асиметр≥њ протилежний напр€му зм≥щенн€ вершини. якщо вершина зм≥щена л≥воруч, маЇмо правосторонню асиметр≥ю, ≥ навпаки. «азначимо, що асиметр≥€ виникаЇ внасл≥док обмеженоњ вар≥ац≥њ в одному напр€м≥ або п≥д впливом дом≥нуючоњ причини розвитку, €ка призводить до зм≥щенн€ центра розпод≥лу. —туп≥нь асиметр≥њ р≥зний Ч в≥д пом≥рного до значного.
як уже зазначалос€, у симетричному розпод≥л≥ характеристики центра Ч середн€, мода, мед≥ана Ч мають однаков≥ значенн€, в асиметричному м≥ж ними ≥снують певн≥ розб≥жност≥. ” раз≥ правосторонньоњ асиметр≥њ  , а в раз≥ л≥восторонньоњ, навпаки,
, а в раз≥ л≥восторонньоњ, навпаки,  . „им б≥льша асиметр≥€, тим б≥льше в≥дхиленн€ (
. „им б≥льша асиметр≥€, тим б≥льше в≥дхиленн€ (

